AFA Deduplication vs vSAN is more than a feature comparison. It is a critical checkpoint for any organization preparing to exit VMware and modernize storage without sacrificing data protection or performance because many VMware alternatives favor a vSAN approach. A vSAN is a software-defined storage architecture that pools local or server-attached storage from multiple servers and presents it as a shared datastore to virtual machines.
For an in-depth discussion on replacing AFAs while addressing performance and resiliency concerns, watch VergeIO and Solidigm’s on-demand webinar.
Any storage platform, vSAN or dedicated storage array, hosting virtual machines must deliver deduplication. Inline deduplication can introduce a heavy processing load in a vSAN because it doesn’t have the benefit of an AFA’s dedicated storage processors.
There is a third architectural option that changes this dynamic. It removes the usual trade-off between deduplication and performance, turning deduplication into a system-wide performance enhancer.
Why Deduplication is Required
Virtualized environments produce high levels of redundant data. Deduplication, if implemented without impacting performance, reduces storage consumption, extends flash media life, and improves the efficiency of protection and replication workflows. These benefits make deduplication a non-negotiable capability in any infrastructure designed to run virtual machines.

The vSAN Deduplication Problem
vSAN technology reached the market before enterprise-ready deduplication was available. Vendors added it later as a separate function. This created a complicated I/O path: writes pass through the hypervisor, into a storage VM, then through a separate deduplication process with its own metadata tables. Each hop adds latency and consumes CPU cycles that could run workloads.
Under peak load, the deduplication engine competes for CPU with both the hypervisor and applications. Intensive hash calculations during busy periods create a bottleneck that directly impacts application responsiveness.
AFA Deduplication: Built for Performance, Priced for Margin
All-Flash Arrays hide this problem by offloading deduplication to dedicated processors in the storage controllers. These processors handle hash and metadata operations without touching server CPU cycles. The design delivers consistent performance regardless of deduplication ratios or workload spikes.
That predictability carries a high cost. AFAs run ten times more expensive per terabyte than standard server-class NVMe SSDs. Proprietary controllers, closed software stacks, and support contracts add cost barriers that make AFAs difficult for many deployments. Deduplication also impacts the effectiveness of RAM Cache, both in the server hosting the VM and at the storage system.
Infrastructure Scaling and Resource Impact
In vSAN environments, scaling the cluster increases the amount of CPU and memory consumed by deduplication. This “hidden tax” reduces the resources available for workloads.
AFAs avoid consuming host resources but add another tier of hardware dedicated to storage. That raises both cost and operational complexity, even though it keeps application servers focused solely on workloads.
Performance in Practice
Real-world measurements show that vSAN deduplication can add almost double digit milliseconds of latency per I/O. Spread across thousands of IOPS, the impact is visible in application performance.
AFAs maintain sub-millisecond deduplication overhead under heavy load because the function is isolated to dedicated hardware.
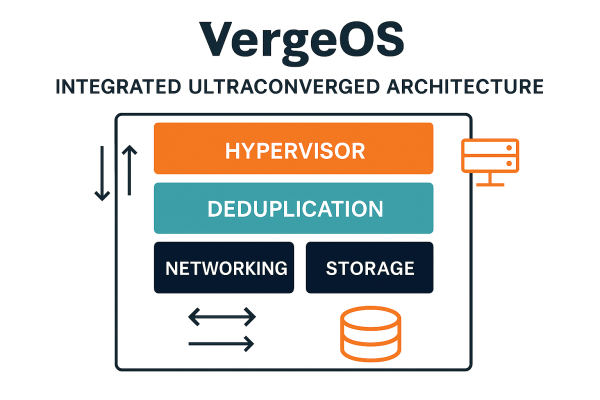
The Third Option: Integrated Ultraconverged Architecture
The limitations above are not inherent to deduplication but are the result of how it is implemented. An integrated ultraconverged architecture like VergeOS eliminates the need to choose between cost and performance. Deduplication, storage, networking, and compute are all native functions of a single operating system.
This approach turns deduplication into an asset. By running it as part of the hypervisor rather than as a bolt-on, the system avoids extra context switches and duplicate metadata structures.
Native Hypervisor Integration
When deduplication is native to the hypervisor, writes are processed with full awareness of storage layout. Hashing and metadata updates occur in the same memory space as core hypervisor functions. Latency drops to near zero, and I/O no longer traverses multiple software layers.
The integrated approach improves performance by reducing the data flowing through the stack, improving cache efficiency, lowering memory pressure, and reducing flash wear.
Network-Level Benefits
Integration extends to the network. Deduplicated data is replicated between sites without re-inflating and re-deduplicating. A 5:1 deduplication ratio produces a direct 5:1 reduction in WAN traffic.
Backup and disaster recovery improve. Snapshots are block-level and independent, avoiding the dependency chains common in AFA designs. Restores complete faster because the system references deduplicated data.
Global Multi-Site Efficiency
A consistent deduplication metadata set across all sites creates a unified storage namespace. Data written in one location can be referenced instantly at another, improving VM mobility and reducing the amount of data that needs to be transferred during migrations. This approach is ideal for ROBO, Venues and Edge locations, especially for Edge AI.
Rethinking Snapshots and Replication
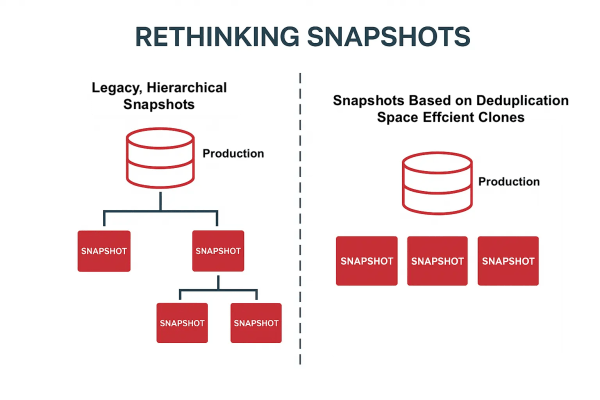
Traditional storage snapshots often form long dependency chains, where each snapshot relies on previous ones. This design wastes space and creates risk—delete or corrupt an earlier snapshot, and the rest are at risk. Replication in these systems is equally inefficient, as it transmits all changes without regard for duplicates already present at the destination.
In an integrated ultraconverged system, snapshots are fully independent and reference a global deduplication map. As a result, snapshots can be taken more frequently, repurposed, and retained indefinitely. Only unique blocks are stored and, during replication, only those blocks new to the target site are sent. For example, a 1 TB snapshot with just 50 GB of unique data transmits only those 50 GB. This block-level awareness reduces WAN usage, shortens transfer times, and lowers storage consumption.
Performance Gains at Scale
Rather than slowing performance, integrated deduplication improves it at scale. As redundancy ratios rise, the performance benefits increase because the working dataset shrinks and cache hit ratios improve.
A Modernization Decision
Post-VMware infrastructure planning no longer has to be a choice between AFA cost and vSAN compromises. Integrated ultraconverged architectures like VergeOS deliver the predictability of dedicated hardware without the expense, while also providing global efficiency capabilities that neither AFAs nor vSAN can match.
When hypervisor, storage, networking, and deduplication operate as a unified system, trade-offs disappear, and the architecture becomes an enabler of performance, scale, and operational simplicity.
George Crump is the Chief Marketing Officer at VergeIO, the leader in Ultraconverged Infrastructure. Prior to VergeIO he was Chief Product Strategist at StorONE. Before assuming roles with innovative technology vendors, George spent almost 14 years as the founder and lead analyst at Storage Switzerland. In his spare time, he continues to write blogs on Storage Switzerland to educate IT professionals on all aspects of data center storage. He is the primary contributor to Storage Switzerland and is a heavily sought-after public speaker. With over 30 years of experience designing storage solutions for data centers across the US, he has seen the birth of such technologies as RAID, NAS, SAN, Virtualization, Cloud, and Enterprise Flash. Before founding Storage Switzerland, he was CTO at one of the nation's largest storage integrators, where he was in charge of technology testing, integration, and product selection.
