Artificial intelligence is now central to IT strategy, yet many organizations assume that meaningful progress requires new infrastructure. The assumption comes from the demands of AI workloads. They require substantial CPU and GPU power, high-throughput storage, and fast data movement. Vendors reinforce this belief by offering AI layers that sit on top of existing stacks, introducing new hardware requirements, licensing rules, and operational steps.
Private AI does not require a complete infrastructure replacement. It requires an infrastructure operating system that integrates AI into the existing environment rather than stacking modules on top of it. Organizations can use the servers already in their data centers, add GPU capability where needed, and repurpose current systems to support data preparation, storage coordination, and orchestration.
Why Private AI Is Different From Public AI
Public AI services are attracting interest because they provide immediate access to large models with no local deployment required. They scale without procurement cycles and avoid infrastructure planning. For many broad use cases, they offer a practical path.

Private AI serves different goals. It keeps sensitive data within the organization and reduces the risk of exposure from external services. It maintains control over training and inference and avoids unpredictable changes in service behavior or pricing. It also delivers consistent performance for workloads that operate near large datasets. These requirements matter to regulated industries and to organizations with proprietary information.
The infrastructure demands are significant. Private AI needs strong compute capability for training and inference, high-throughput storage for large datasets, and a network that moves data between stages quickly. It also needs operational flexibility. Training saturates GPUs and CPUs for long periods. Inference produces steady but uneven demand. Supporting both in the same environment requires an operating system that allocates resources dynamically and avoids fragmented control paths.
Traditional virtualization software was not built for this type of integration. It separates compute, storage, and networking into distinct domains that coordinate through APIs. When vendors add AI functions, they add layers that depend on those services. Each addition increases overhead and reduces hardware longevity.
How Layered AI Architectures Increase Complexity
AI is following the same expansion pattern as earlier infrastructure features. When network virtualization grew in popularity, vendors added it as a separate layer. When software-defined storage emerged, it followed the same design. Each capability introduced its own management tasks, background processes, and integration needs. AI continues this trend.
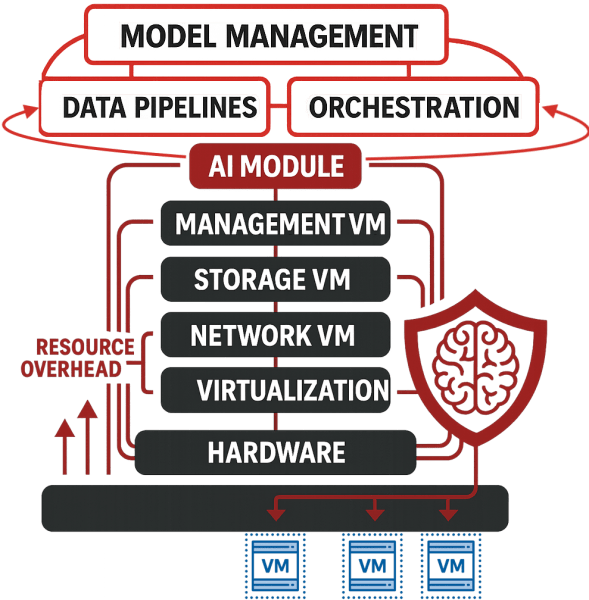
Many vendors add AI as a collection of modules. One manages models, another coordinates data pipelines, and a third controls orchestration. Each module has its own control plane and resource footprint. Each introduces internal processes that run continuously.
This fragmentation matters because AI produces sustained pressure on the environment. Training pushes GPU utilization to full capacity for long durations. Inference creates steady CPU activity and demands predictable latency. Both depend on fast access to large datasets stored across the cluster. Any inefficiency slows training and increases inference delay.
Layered AI architectures shorten hardware life. They assume access to recent CPUs with advanced instruction sets, large memory pools, and fast interconnects. Older servers that perform well for most workloads fall short of these requirements. The limitation is not the hardware. It is the software overhead introduced by module stacking.
A Unified Approach to AI Infrastructure
AI infrastructure works best when the platform integrates AI capability into its base architecture. A unified infrastructure operating system coordinates compute, storage, networking, and AI within a single codebase. This unification eliminates redundant services, reduces data movement, and minimizes latency.
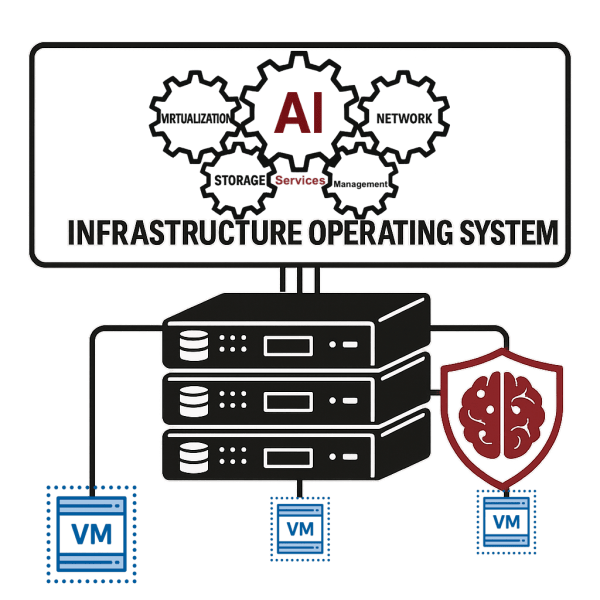
Integration simplifies operations. Administrators manage AI workloads through the same interface they use for virtual machines, storage volumes, and networks. There are no external consoles to learn and no integration projects to complete. The same scheduling engine coordinates all workloads, which improves predictability.
A unified approach extends hardware usefulness. Older servers handle data preparation, storage coordination, and orchestration, while nodes with GPU capacity support training and high-throughput inference. Organizations add GPUs to existing servers instead of replacing systems that still have strong CPU performance, memory capacity, and I/O bandwidth.
With a unified approach to AI, the environment is ready to provide high-value inference on day one. Load your private documents or text exports of databases, and start asking questions.
For a deeper examination of server longevity and how unified designs keep hardware productive for years, see: Extending Server Longevity.
Using Existing Servers for Private AI
The belief that AI requires new infrastructure comes from two incomplete assumptions. The first is that training requires cutting-edge hardware. The second is that older servers lack the performance to contribute. Both assumptions fail to account for the range of AI workload types.
Training large models benefits from modern GPUs, yet many organizations focus on smaller models or fine-tuning tasks. These workloads run effectively on a mix of CPUs and GPUs. Inference often runs well on CPUs, particularly for predictable usage patterns. Data preparation, feature extraction, and storage coordination run efficiently on servers that organizations already own.
A balanced environment assigns workloads based on their needs. GPU-capable systems support training and heavy inference. Older servers support data pipelines and lower-intensity inference. This approach keeps current hardware productive and reduces capital expense.
Adding GPUs to existing systems is often straightforward. PCIe-based GPUs work in standard server chassis, and servers deployed five or six years ago usually have the CPU and memory required for AI tasks once GPU capacity is present. Organizations can start with a small cluster, introduce GPU resources to one or two nodes, validate their AI workloads, and expand as needed.
VergeOS as an Example
VergeOS illustrates the unified approach. The platform integrates AI as a service within the infrastructure operating system. The capability appears in the interface and activates with no extra modules or configuration steps. It runs efficiently on existing servers, including hardware that other vendors have deprecated. Older systems support data preparation and storage, while GPU-enabled nodes support training and inference. All capabilities come included with no licensing add-ons.
Organizations report keeping servers productive for eight to ten years. They extend hardware value while building private AI environments, avoiding the disruption of large-scale infrastructure replacement.
With an infrastructure operating system like VergeOS, you can replace VMware while extending server longevity and laying the foundation for private AI. For more on using existing hardware to modernize infrastructure, check out VergeIO’s upcoming live webinar: Replace VMware, Not Your Servers.
George Crump is the Chief Marketing Officer at VergeIO, the leader in Ultraconverged Infrastructure. Prior to VergeIO he was Chief Product Strategist at StorONE. Before assuming roles with innovative technology vendors, George spent almost 14 years as the founder and lead analyst at Storage Switzerland. In his spare time, he continues to write blogs on Storage Switzerland to educate IT professionals on all aspects of data center storage. He is the primary contributor to Storage Switzerland and is a heavily sought-after public speaker. With over 30 years of experience designing storage solutions for data centers across the US, he has seen the birth of such technologies as RAID, NAS, SAN, Virtualization, Cloud, and Enterprise Flash. Before founding Storage Switzerland, he was CTO at one of the nation's largest storage integrators, where he was in charge of technology testing, integration, and product selection.
