Organizations that successfully automate infrastructure provisioning often struggle to automate data protection. Teams deploy Terraform to build virtual machines and Ansible to configure operating systems. Still, the backup and recovery workflow remains largely an automation silo driven by the backup or disaster recovery application. Administrators create snapshot schedules via storage array interfaces, configure backup jobs via separate software consoles, and manage replication policies via yet another management layer.
Key Terms & Concepts
Data Protection Automation: The practice of using code-based tools (Terraform, Ansible, Packer) to automate backup schedules, snapshot policies, replication configurations, and recovery procedures rather than managing these tasks manually through separate vendor interfaces.
Storage Array Snapshots: Point-in-time copies of data created at the storage hardware level through vendor-specific APIs. These snapshots provide the first layer of data protection but require separate integration code for each storage platform.
Hypervisor Snapshots: Virtual machine state captures that include memory, disk state, and configuration. These operate independently from storage snapshots and use different APIs for management and automation.
Backup Software: Third-party applications (like Veeam, Commvault, or Rubrik) that provide additional data protection layers through application-aware backups, retention policies, and recovery capabilities. Each platform exposes its own API for automation.
Replication Systems: Technologies that copy data between sites for disaster recovery purposes. Replication can occur at the storage array level, through backup software, or through hypervisor mechanisms—each requiring separate configuration and automation paths.
Multi-Layer Protection: The traditional approach where data protection spans multiple independent systems (storage snapshots, hypervisor snapshots, backup software, replication) that must be coordinated through separate APIs and management interfaces.
API Fragmentation: The condition where each component in the infrastructure stack exposes different application programming interfaces with incompatible authentication models, object schemas, and versioning approaches, preventing unified automation.
Orchestration Burden: The operational complexity of coordinating protection workflows across multiple independent systems that do not communicate naturally, requiring custom integration code to handle timing, failure recovery, and state synchronization.
Unified Infrastructure: An architectural approach that integrates compute, storage, networking, and data protection into a single operating system with one API, eliminating the need to coordinate across multiple independent vendors and platforms.
ioGuardian: A secondary protection service that integrates with unified infrastructure platforms to provide additional backup capabilities without introducing separate backup software APIs or management complexity.
Infrastructure as Code (IaC): The practice of managing infrastructure through machine-readable definition files (Terraform, Ansible) rather than manual configuration, enabling version control, testing, and automated deployments.
Golden Image: A pre-configured, version-controlled template created by tools like Packer that serves as the standardized foundation for all virtual machine deployments, ensuring consistency across environments.
Declarative Infrastructure: An approach where infrastructure definitions describe the desired end state rather than step-by-step procedures. Tools like Terraform compare desired state to actual state and automatically determine what changes are needed.
Configuration Drift: The gradual divergence of system configurations from their intended state, typically caused by manual changes or inconsistent automation practices across multiple management interfaces.
Single-API Model: An infrastructure architecture where all services (compute, storage, networking, data protection) are managed through one consistent API, dramatically simplifying automation integration and eliminating vendor-specific conditional logic.
The problem is not a lack of APIs. Every component in the data protection stack exposes programmatic interfaces. The problem is that data protection spans multiple independent systems that require separate automation paths. Fragmented infrastructure breaks automation, and data protection suffers more than any other operational domain because it depends on coordination across storage, hypervisor, backup software, and replication layers.
The Multi-Layer Protection Problem
Data protection in traditional virtualized environments operates across at least four independent layers, each with its own management interface and API structure.
Storage array snapshots provide the first layer. Arrays expose snapshot capabilities through vendor-specific REST APIs. Creating a snapshot policy requires authentication to the variety, navigating its object model, and issuing commands in the format that the specific vendor expects. A snapshot schedule that works on one array vendor requires complete rewriting for another vendor’s platform. Organizations running multiple storage families maintain separate Terraform modules or Ansible roles for each array type.
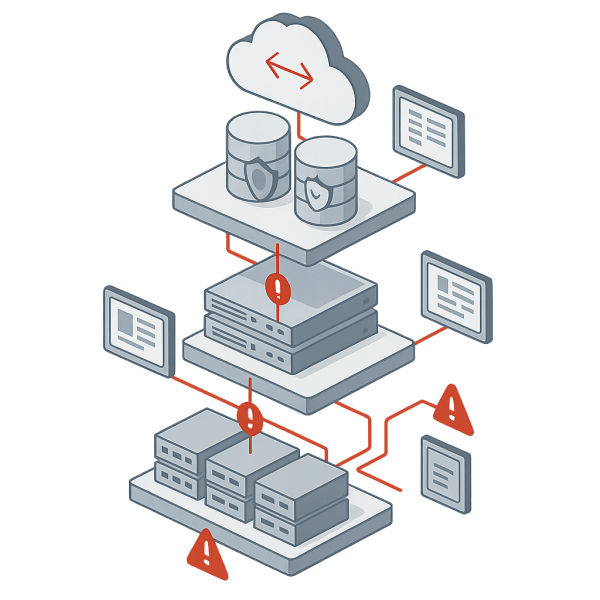
Hypervisor snapshots operate independently from storage. VMware snapshots use vCenter APIs. Other hypervisors expose different snapshot mechanisms through their own interfaces. Hypervisor snapshots capture VM state and memory, but they depend on storage snapshots for capacity efficiency. The two layers coordinate poorly. Automation must account for timing, retention alignment, and the interaction between hypervisor and storage snapshot mechanisms.
Backup software introduces a third layer. Veeam, Commvault, Rubrik, and other backup platforms expose their own APIs for job scheduling, retention policies, and restore operations. These APIs differ substantially across vendors. Backup software must integrate with both storage arrays and hypervisors to perform efficient backups. The integration points vary by backup vendor, storage vendor, and hypervisor platform. Terraform modules that define backup policies for one backup platform do not transfer to another.
Replication systems add the fourth layer. Storage array replication operates independently from backup software replication. Some organizations replicate snapshots at the storage layer. Others replicate backup data through the backup software’s replication engine. Some combine both approaches. Each replication path requires separate configuration, monitoring, and failover procedures. Automation must navigate these separate replication mechanisms without creating conflicts or gaps.
Why Automation Fragments
The fragmentation stems from architectural independence. Each protection layer evolved separately to solve specific problems. Storage vendors optimized snapshot efficiency for their arrays. Hypervisor vendors built snapshot mechanisms that capture VM state. Backup software vendors created application-aware backup engines. None of these layers was designed to integrate cleanly with the others.
The API differences compound across vendors. An organization running Dell storage, VMware hypervisors, and Veeam backup maintains three separate automation paths for data protection. Terraform modules that create snapshot policies must include Dell-specific resource definitions, VMware-specific snapshot commands, and Veeam-specific job configurations. The modules cannot share code because each vendor exposes different object models, authentication patterns, and versioning schemes.
Ansible playbooks face the same fragmentation. A role that configures backup policies for VMware VMs running on Dell storage uses completely different tasks than a role targeting VMs on HPE storage. The same logical operation—protect this VM with snapshots and backup—requires vendor-specific implementations across storage, hypervisor, and backup layers.
Monitoring inherits this complexity. Prometheus exporters for storage arrays use different metric structures than exporters for backup software. Grafana dashboards require separate queries for storage snapshot capacity, backup job status, and replication health. Alert rules multiply because each protection layer exposes health data through incompatible schemas. Teams build separate monitoring stacks for each protection layer rather than a unified observability stack.
The Orchestration Burden
Coordinating protection across these layers creates operational challenges that automation struggles to address. Application-consistent backups require snapshot coordination between the hypervisor and the storage system. The hypervisor must quiesce the VM. The storage must generate the snapshot. The backup software must recognize the snapshot and initiate the backup job. The timing must align precisely, or the backup fails.
Automating this workflow requires Terraform or Ansible to orchestrate across three separate APIs with different authentication models and object schemas. The module or role must handle failures at any layer and roll back changes across systems that do not coordinate naturally. Error handling becomes complex because each API returns different error codes and messages for similar failure conditions.

Replication coordination adds another dimension. Storage array replication and backup software replication operate independently. Automation must track which VMs replicate through storage-level mechanisms and which replicate through backup software. The two approaches require different Terraform resources and Ansible tasks. Organizations running both replication types maintain parallel automation paths that do not share logic.
DR testing exposes the brittleness. A test failover requires coordinating storage snapshot promotion, VM registration in the DR hypervisor, and backup software awareness of the new VM locations. Traditional automation handles these steps through separate modules that assume manual coordination. Full automation requires building orchestration logic that most teams never complete because the complexity exceeds the benefit.
The Single-API Alternative
Unified infrastructure operating systems approach data protection differently. Rather than coordinating across independent storage, hypervisor, and backup layers, these platforms integrate protection capabilities into the infrastructure itself.

The model treats snapshots, replication, and backup as infrastructure services rather than external systems. Terraform modules reference protection policies through a single API. Ansible roles configure retention and replication without requiring navigation of vendor-specific storage interfaces. Prometheus monitors protection health through unified metrics that cover snapshots, replication, and recovery capabilities.
This architecture eliminates the orchestration burden. Application-consistent protection does not require cross-API coordination because the platform handles VM quiescence, snapshot creation, and backup coordination internally. Terraform defines the protection intent. The platform implements the workflow across compute, storage, and data protection layers.
Replication simplifies because it operates at the infrastructure level rather than through separate storage and backup mechanisms. A single Terraform resource defines a replication policy. The platform handles snapshot replication, network optimization, and consistency verification. Ansible roles configure failover procedures through the same API that manages primary site operations.
Monitoring consolidates naturally. Prometheus exporters interact with one API that exposes snapshot capacity, replication status, and recovery point objectives through consistent metric structures. Grafana dashboards use unified queries. Alert rules remain simple because protection health data follows predictable patterns across all infrastructure components.

To see how infrastructure automation works on unified platforms, register for VergeIO’s webinar: Building an End-to-End Automation Chain. During the webinar, they demonstrate how Packer, Terraform, and Ansible operate on infrastructure designed for automation rather than fighting against fragmentation.
How VergeOS Implements Unified Protection
VergeOS demonstrates this model through integrated data protection capabilities that operate through the same API that manages compute, storage, and networking.
The platform provides independent snapshots at the virtual machine level or virtual data center level without depending on external storage arrays. Terraform modules create snapshot schedules through VergeOS resources. Ansible roles modify retention policies through VergeOS tasks. The automation code remains consistent regardless of underlying hardware because VergeOS abstracts snapshot mechanisms from physical storage.
ioGuardian integration adds secondary protection without introducing separate backup software APIs. VergeOS treats ioGuardian as an integrated service. Terraform defines which VMs send snapshots to ioGuardian. Ansible configures ioGuardian retention policies. Prometheus monitors ioGuardian capacity and replication status. The automation framework never interacts with ioGuardian’s API directly because VergeOS handles the integration.
Replication operates through the same infrastructure API. Terraform modules define replication targets and policies. VergeOS handles snapshot transfer, bandwidth optimization, and consistency verification. DR site infrastructure receives replicated snapshots and makes them available for recovery operations. The process requires no separate replication software and no coordination across independent storage systems.
The result is data protection automation that uses the same Terraform providers, Ansible collections, and Prometheus exporters as infrastructure provisioning. Teams write protection policies alongside compute and network definitions. The modules remain portable across clusters because VergeOS maintains consistent protection capabilities regardless of hardware configuration. DR sites use identical automation because the platform behaves identically across all locations.
| Aspect | Fragmented Multi-Layer Protection | Unified Single-API Protection |
|---|---|---|
| API Complexity | Four separate APIs for storage arrays, hypervisor snapshots, backup software, and replication systems. Each with different authentication models. | Single API manages all protection services (snapshots, backup, replication) through the infrastructure operating system. |
| Terraform Modules | Separate modules for each vendor and product. Storage snapshot policies require vendor-specific resources. Modules cannot be shared across platforms. | Protection policies defined through standard infrastructure resources. Same modules work across all clusters regardless of underlying hardware. |
| Ansible Roles | Different roles for each storage vendor, backup platform, and replication system. Roles include conditional logic for firmware versions and product variations. | Protection configuration uses unified tasks. No vendor-specific conditionals or platform detection logic required. |
| Orchestration | Manual coordination required across storage, hypervisor, and backup layers. Custom error handling for each platform. Timing synchronization fragile. | Platform handles coordination internally. Application-consistent protection occurs automatically without orchestrating across separate systems. |
| Hardware Refresh | New storage models break existing automation. API changes require module updates. Firmware upgrades expose incompatible endpoints. | Hardware changes invisible to automation. New servers join clusters without requiring code updates. Platform maintains abstraction across generations. |
| Vendor Migration | Complete automation rewrite required. All Terraform modules, Ansible roles, and monitoring integrations must be rebuilt for new vendor APIs. | No migration impact on automation code. Protection services remain consistent regardless of underlying hardware vendor changes. |
| Monitoring Integration | Separate Prometheus exporters for each protection layer. Grafana dashboards require vendor-specific queries. Alert rules multiply across platforms. | Single Prometheus exporter provides unified metrics. Grafana dashboards use consistent queries. Alert rules remain simple across all protection components. |
| DR Testing | Separate automation for production and DR sites due to platform differences. Manual coordination required for failover testing. Configuration drift between sites. | Identical automation at both sites. DR tests execute through same playbooks as production. Perfect environment mirroring through consistent API. |
| Maintenance Burden | Time spent updating automation often exceeds time saved. Each vendor update, firmware change, or product addition requires code modifications. | Minimal maintenance. Protection automation remains stable across infrastructure changes. Updates focused on new features rather than compatibility fixes. |
| Code Complexity | Modules contain conditional branches for each vendor. Roles include hardware detection and version checks. State management fragments across platforms. | Clean, readable code describes intent. No vendor-specific conditionals. Single state management through unified platform. |
| Recovery Speed | Manual steps required to coordinate restoration across storage, hypervisor, and backup layers. Documentation often out of sync with actual systems. | Rapid recovery through automated deployment. Infrastructure code serves as accurate documentation. Consistent restoration process across all sites. |
| Team Expertise | Staff must understand multiple vendor APIs, backup software integrations, and platform-specific quirks. Institutional knowledge critical. | Staff learns one platform model. Knowledge more portable. Less dependency on individuals who understand vendor-specific complexity. |
Operational Outcomes
Unified data protection changes operational patterns. Organizations automate backup schedules, snapshot retention, and replication policies through the same workflows they use for infrastructure provisioning. Terraform modules define protection alongside the VMs they protect. Ansible roles configure retention during application deployment rather than as separate post-deployment tasks.
DR testing becomes repeatable. Terraform modules that provision the DR environment include protection policy definitions. Running the module at the DR site creates infrastructure with identical protection characteristics. Failover tests run through Ansible playbooks that use the same API as during normal operations. The tests become reliable because the automation does not depend on coordinating across independent systems.
Monitoring provides unified visibility. Prometheus collects protection metrics through the same exporters that monitor compute and storage. Grafana dashboards show snapshot capacity, replication lag, and recovery point age alongside infrastructure health. Teams maintain one monitoring stack rather than separate systems for infrastructure and data protection.
The automation code becomes more straightforward and more maintainable. Terraform modules drop the conditional logic required to navigate different storage array APIs. Ansible roles remove vendor-specific tasks for backup software integration. The codebase shrinks because one API handles protection across all infrastructure components.
Organizations gain data protection automation that scales predictably. The framework does not fragment as environments grow because the platform maintains consistent protection capabilities across clusters and hardware generations. Protection policies remain stable through refresh cycles because the infrastructure abstracts protection mechanisms from physical components.
Key Takeaways
Data protection automation fails because it spans multiple independent systems that were never designed to coordinate. Storage snapshots, hypervisor snapshots, backup software, and replication systems each require separate APIs, authentication models, and integration code.
Traditional infrastructure operates across at least four protection layers with incompatible management interfaces. Teams must coordinate storage array snapshots, hypervisor state captures, backup job scheduling, and replication policies through separate vendor-specific APIs that share no common patterns.
API fragmentation multiplies across vendors and products. An organization running Dell storage, VMware hypervisors, and Veeam backup maintains three completely separate automation paths for data protection. Terraform modules and Ansible roles cannot share code because each vendor exposes different object models and authentication patterns.
Infrastructure as Code tools do not abstract storage differences. Terraform providers and Ansible collections are thin wrappers around the same REST APIs that direct integration uses. The underlying complexity remains—teams replace REST calls with HCL or YAML while maintaining the same conditional logic and platform-specific parameters.
Coordinating protection across layers creates brittle orchestration. Application-consistent backups require precise timing between hypervisor quiesce, storage snapshot creation, and backup job initiation. Automation must handle failures at any layer and roll back changes across systems that do not coordinate naturally.
Unified infrastructure platforms integrate protection into the operating system itself. Rather than coordinating across independent storage, hypervisor, and backup layers, these platforms treat snapshots, replication, and backup as infrastructure services accessible through a single API.
Single-API models eliminate orchestration complexity. Terraform modules reference protection policies through one API. Ansible roles configure retention without navigating vendor-specific storage interfaces. Prometheus monitors protection health through unified metrics that cover snapshots, replication, and recovery capabilities.
VergeOS demonstrates unified protection through integrated capabilities. The platform provides independent snapshots without external storage arrays, ioGuardian integration without separate backup software APIs, and replication through the same infrastructure API used for compute and networking.
Automation code becomes dramatically simpler on unified platforms. Teams write protection policies alongside compute definitions using the same Terraform providers and Ansible collections. Modules remain portable across clusters because the platform maintains consistent protection capabilities regardless of hardware configuration.
DR testing becomes repeatable and reliable. Terraform modules that provision DR environments include protection policy definitions. Running the module creates infrastructure with identical protection characteristics. Tests execute through playbooks that reference the same API used during normal operations without coordinating across independent systems.
Frequently Asked Questions
Why does data protection automation fail when infrastructure provisioning automation succeeds?
Infrastructure provisioning typically operates at a single layer (the hypervisor or cloud control plane), while data protection spans four independent layers: storage arrays, hypervisors, backup software, and replication systems. Each layer has its own API, authentication model, and object schema. Provisioning automation coordinates fewer systems, while protection automation must orchestrate across platforms that were never designed to work together.
Can Infrastructure as Code tools like Terraform solve the multi-vendor API problem?
No. Terraform providers and Ansible collections are thin wrappers around vendor-specific APIs. They translate HCL or YAML into REST API calls, but they don’t abstract the underlying differences. You still maintain separate modules for each storage vendor, each backup platform, and each replication system. The complexity moves from direct API calls into IaC syntax, but it doesn’t disappear.
How much time do teams typically spend maintaining data protection automation versus building it?
Organizations often discover they spend more time updating automation than they saved by implementing it. Hardware refresh cycles require module updates when new storage models introduce API changes. Firmware upgrades expose new endpoints that break existing code. Backup software updates change resource definitions. Multi-vendor environments multiply this maintenance burden across every platform combination.
What happens to data protection automation during storage vendor migrations?
Complete rewrites are required. Moving from Dell PowerStore to HPE Primera means rewriting every Terraform module that creates snapshot policies, every Ansible role that configures backup jobs, and every monitoring integration. The storage platform change cascades through the entire automation framework because none of the code is portable across vendors.
How does unified infrastructure eliminate the need for separate backup software APIs?
Unified platforms integrate data protection into the infrastructure operating system itself. Services like ioGuardian in VergeOS operate as integrated components rather than separate products. Terraform modules reference protection policies through the same API that manages compute and networking. There’s no separate backup software to integrate because protection is a native infrastructure service.
Can you automate data protection without unified infrastructure?
Yes, but you accept significant complexity. You’ll maintain separate automation paths for storage snapshots, hypervisor snapshots, backup software, and replication systems. You’ll write orchestration logic to coordinate across these layers. You’ll handle version-specific conditionals for each platform. It’s possible, but the maintenance burden grows with each vendor, product, and firmware version in the environment.
How does single-API data protection affect DR testing procedures?
DR testing becomes repeatable and reliable because the same automation code works at both sites. Terraform modules that provision production infrastructure include protection policies. Running those modules at the DR site creates an environment with identical protection characteristics. Tests execute through Ansible playbooks that reference the same API used during normal operations, without coordinating across independent backup and replication systems.
What about organizations that already invested heavily in multi-vendor data protection stacks?
The investment represents sunk cost. The question is whether to continue paying the ongoing maintenance burden or migrate to a simpler architecture. Organizations should measure time spent updating automation against time saved by automation. If maintenance exceeds savings, the automation framework is generating negative value. Storage refresh cycles and VMware exits provide natural migration windows to address architectural problems.
Does unified data protection mean vendor lock-in?
Every infrastructure decision involves trade-offs. Traditional multi-vendor approaches avoid platform lock-in but create automation lock-in—your code becomes so customized to specific vendor combinations that changing any component requires extensive rewrites. Unified platforms create platform dependency but eliminate automation complexity. The question is which lock-in is more expensive to your organization over time.
How do monitoring and observability work with unified data protection?
Dramatically simpler. Prometheus exporters interact with one API that exposes snapshot capacity, replication status, and recovery point objectives through consistent metric structures. Grafana dashboards use unified queries instead of vendor-specific ones. Alert rules remain simple because protection health data follows predictable patterns across all infrastructure components. Teams maintain one monitoring stack instead of separate systems for storage, backup, and replication.
George Crump is the Chief Marketing Officer at VergeIO, the leader in Ultraconverged Infrastructure. Prior to VergeIO he was Chief Product Strategist at StorONE. Before assuming roles with innovative technology vendors, George spent almost 14 years as the founder and lead analyst at Storage Switzerland. In his spare time, he continues to write blogs on Storage Switzerland to educate IT professionals on all aspects of data center storage. He is the primary contributor to Storage Switzerland and is a heavily sought-after public speaker. With over 30 years of experience designing storage solutions for data centers across the US, he has seen the birth of such technologies as RAID, NAS, SAN, Virtualization, Cloud, and Enterprise Flash. Before founding Storage Switzerland, he was CTO at one of the nation's largest storage integrators, where he was in charge of technology testing, integration, and product selection.
