Introduction
Multi-site IT infrastructure has become standard practice, with organizations deploying workloads across edge computing locations, remote branch offices (ROBOs), large venues, and core data centers. Each site type has distinct infrastructure requirements—some need only two or three servers, while others demand high-density clusters or specialized hardware for AI workloads.
Rather than fighting this hardware diversity through rigid standardization, the path to multi-site IT efficiency lies in embracing flexible hardware deployment while enforcing consistent infrastructure software management. When one unified infrastructure operating system manages diverse hardware across all distributed sites, organizations achieve both procurement flexibility and operational simplicity. This approach reduces IT complexity by treating hardware selection as a tactical decision while maintaining software management as a strategic, standardized process. These opposites, when combined, deliver counterintuitive results:
- Reduced IT Operational Complexity
- Faster Deployment
- Simplified Operations
Multi-site IT has become the norm, with organizations running workloads at the Edge, across ROBOs, within large Venues, and back at the core data center. Each location type has different requirements, and it is not uncommon for organizations to operate two of these site types at once, or even all three.
- ROBOs support small groups of employees and require basic services like domain controllers, file shares, and light application hosting. They need cost-efficient infrastructure with minimal on-site management.
- Venues—such as entertainment centers, retail spaces, or stadiums—depend on IT for customer-facing operations like point-of-sale, ticketing, and video analytics. These sites cannot tolerate downtime during business hours and demand non-disruptive upgrades and rapid recovery.
- Edge locations process IoT or sensor data close to the source, or run inference workloads where latency is critical. They must stay resilient even when disconnected from the core or the cloud. The diversity of these environments creates a wide range of hardware needs, but the common thread is the requirement for consistent, centralized software management.
Standardizing hardware across all these environments is impractical and, in many cases, self-defeating. These concerns exacerbate in multi-site IT but are evident in the core data center as well, and are part of a broader infrastructure problem.
The Current State: Backwards Priorities
IT organizations follow conventional wisdom when approaching multi-site deployments. They standardize hardware while accepting software inconsistency across locations. This conventional approach creates the worst possible combination for multi-site IT teams, but it reflects decades of established “best” practices.
Hardware standardization encourages IT teams to create approved server lists, negotiate volume discounts with preferred vendors, and establish support contracts that cover identical equipment. This worked when infrastructure lived in centralized data centers and strict hardware compatibility lists kept platforms stable. But in distributed environments with vastly different requirements, rigid hardware standards become a liability. Supply chain disruptions stall rollouts because no alternatives are allowed.
- Remote offices get oversized enterprise-grade servers they don’t need.
- Edge sites with AI inference workloads are stuck with general-purpose systems that can’t handle GPUs.
- Venues are not afforded the independence and resilience needed to maintain sales under peak load.
Configuration drift inevitably follows, because getting work done takes precedence over following the standard.
To learn more about unifying Edge, ROBO, and Venue locations while exiting VMware, register for VergeIO’s live webinar and demonstration.
Software inconsistency represents the other half of conventional thinking. Different site types have long relied on different platforms based on local needs and constraints. VMware vSphere runs at the core data center. Hyper-V operates at branch offices because of licensing agreements. Edge-specific hyperconverged solutions get chosen for fleet management specialization or lower cost. Bare-metal deployments run at the edge to minimize physical space overhead. Each choice made sense locally, but together they create a patchwork that multiplies complexity. Even sites of the same type diverge over time—one ROBO runs Windows Server while another uses Linux NAS; one Venue standardizes on a hypervisor while another adopts a separate orchestration tool.
The result is operational drag across both dimensions. Strict hardware rules not only delay rollouts as sites wait for specific server models stuck in supply-chain bottlenecks, but they also prevent IT from matching the right hardware to the right job at each location. A small ROBO with light workloads ends up saddled with oversized enterprise servers. Edge sites that require GPUs or high-performance storage are forced onto general-purpose systems that can’t deliver. Meanwhile, software diversity across sites forces IT staff into multiple interfaces, complicates management workflows, and increases the risk of errors during routine operations or recovery events.
But what if conventional wisdom has it backwards? What if the path to simpler multi-site IT lies in doing the exact opposite?
Hardware Inconsistency = Flexibility
The right approach to multi-site IT starts with accepting hardware diversity as a feature, not a bug. When IT teams abandon rigid hardware standardization, they gain procurement freedom, workload optimization, and lifecycle flexibility that conventional approaches cannot match.
Procurement freedom is critical in today’s supply chain environment. Multi-site IT cannot depend on a single vendor when lead times stretch for months and prices change weekly. A ROBO deployment that waits six months for approved servers costs more in lost productivity than any discount saves. With hardware flexibility, IT can source from multiple vendors, take advantage of availability, and avoid vendor lock-in.
The ability to match workloads to hardware delivers immediate benefits. A remote office running file shares and print services needs modest compute and storage. Forcing that site to use the same enterprise-grade servers as the core wastes budget and power. An edge site processing video analytics may require GPU acceleration and high-performance storage that general-purpose servers cannot provide. When hardware choices align with site requirements, each location operates more efficiently and costs less to run.
In addition to meeting today’s demands, flexibility will support a more natural site evolution. A new ROBO may begin with two modest servers. As it grows, IT can add hardware tailored to new workloads rather than overbuying upfront. Scaling becomes tactical—IT adds what’s needed, when it’s needed.
Beyond scaling flexibility, lifecycle management improves. Older servers retired from the core can continue to serve at smaller sites. Hardware can move between locations, extending its useful life and maximizing ROI. Newer systems with advanced features can be placed where they deliver the most value, reducing capital peaks and smoothing refresh cycles.
The key requirement is not hardware uniformity but software consistency. When the infrastructure operating system runs on any x86 hardware, IT gains procurement flexibility without sacrificing operational consistency. Hardware diversity becomes manageable when software consistency handles the complexity.
Comparing Hardware Consistency vs. Hardware Flexibility
| Aspect | Strict Hardware Standards | Hardware Flexibility |
|---|---|---|
| Procurement | Single vendor dependency, long lead times | Multiple vendor options, faster sourcing |
| Supply Chain Risk | Delays halt entire deployments | Alternative hardware keeps projects moving |
| Site Matching | One-size-fits-all approach | Right hardware for specific workloads |
| Cost Efficiency | Overbuying for small sites | Appropriately sized equipment |
| Scaling | Must overbuy upfront | Add exactly what’s needed, when needed |
| Lifecycle Management | Forced refresh cycles | Cascade hardware between sites |
| Vendor Relations | Locked into single supplier | Negotiating leverage with multiple options |
| Emergency Deployment | Wait for approved hardware | Deploy on available equipment |
| Operational Complexity | Simple procurement, complex operations | Complex procurement, simple operations |
| Growth Pattern | Expensive, lumpy investments | Smooth, tactical expansion |
| Hardware Utilization | Underutilized at many sites | Optimized for actual requirements |
| Risk Profile | Single point of failure | Distributed risk across suppliers |
Software Consistency = Simplicity
While hardware should vary by site, software must remain constant across the entire multi-site environment. A single infrastructure operating system that spans Edge, ROBO, Venues, and Core locations transforms operational complexity into manageable consistency.

The primary responsibility of this infrastructure operating system is to enable hardware diversity without creating a management nightmare. This requires a single-code base architecture that abstracts not only across server hardware, but also storage and networking. When software masks the differences between Intel and AMD processors, NVMe and SATA storage, or Cisco and HPE networking gear, IT teams gain hardware freedom without operational complexity. Inconsistent hardware becomes consistent through software abstraction.
With abstraction in place, unified operations eliminate the expertise fragmentation that plagues multi-site IT. Instead of maintaining specialists in VMware, Hyper-V, and various hyperconverged platforms, IT teams develop deep knowledge in one system. This allows them to become true specialists rather than shallow generalists spread across too many platforms. Expertise transfers directly from site to site: a technician who understands storage provisioning at the core can apply that same knowledge at any remote location. Training becomes focused rather than scattered across multiple technologies.
Centralized policy management further enforces consistency. Backup schedules, replication rules, security policies, and compliance settings are all built into the infrastructure operating system and deployed uniformly across all sites. Changes made at headquarters propagate automatically, eliminating configuration drift and making policy violations visible immediately instead of being discovered during audits or worse, during a breach. Crucially, policies are enforced locally; as a result, sites remain resilient even when WAN connectivity fails.
Single-pane-of-glass monitoring and standardized operations reduce human error across all locations. Health, performance, and compliance status are consolidated into a single interface, with alerts now feeding into a unified stream rather than being scattered across multiple consoles. Identical procedures for provisioning, backup, recovery, and maintenance apply everywhere, documentation is universal, and onboarding new staff is faster.
The benefits compound as the number of sites grows. Managing ten locations with consistent software is marginally more complex than managing one. Managing ten locations with different platforms multiplies complexity tenfold. Consistency scales; diversity fragments.
Software uniformity transforms multi-site IT from a collection of individual deployments into a unified infrastructure that happens to run in multiple locations. This consistency forms the foundation; Virtual Data Centers are where hardware freedom and software consistency meet.
Where Opposites Meet: Virtual Data Centers (VDCs)
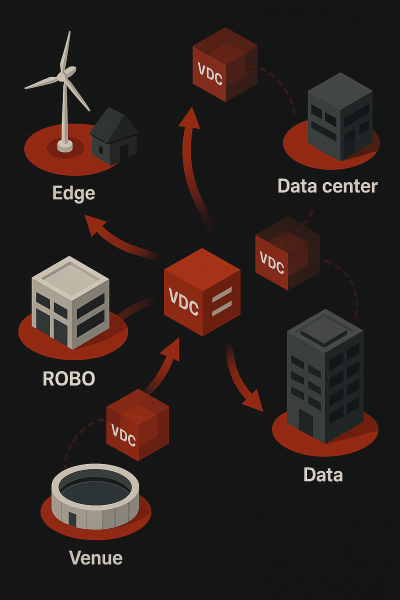
Virtual Data Centers which provide secure, nested multi-tenancy are the clearest demonstration of how hardware freedom and software consistency work together. A VDC encapsulates everything needed to run workloads at a site—virtualization, storage, networking, and security—into a single, portable unit that operates on any compatible hardware while maintaining identical management characteristics.
Each site becomes its own VDC, regardless of physical size or hardware composition. A two-server ROBO runs the same architecture as a hundred-server core data center. The software presents identical interfaces, enforces the same policies, and delivers the same capabilities. Hardware differences become invisible to operations teams.
Encapsulation also solves the mobility problem that has plagued multi-site IT. Because a VDC exists as a complete virtual environment, it can move intact to different hardware without modification. A VDC on aging servers at Site A can be transferred to newer hardware at Site B, with applications, data, networking, and security policies intact. Workloads continue running as if nothing changed.
This mobility enables practical outcomes that traditional infrastructure cannot deliver. Disaster recovery involves activating a VDC on available hardware, rather than rebuilding complex configurations. Maintenance involves temporarily relocating a VDC, rather than scheduling downtime. Consolidation merges multiple VDCs onto shared infrastructure without rearchitecting applications or reconfiguring networks.
IT Patch sees similar gains because VDCs make patch testing practical and easy. An entire site can be cloned into a test environment, updated, and validated before applying the same changes in production. This reduces upgrade risk and gives IT the confidence to update within hours of patch release.
The abstraction layer that makes VDCs possible handles hardware differences automatically. Storage from different vendors presents uniform capacity. Network interfaces from various manufacturers provide consistent connectivity and security. Virtualization resources from different server generations offer standardized processing. The VDC sees homogeneous resources regardless of the heterogeneous hardware underneath.
With VDCs, moving, cloning, or recovering a site becomes a repeatable, predictable process no matter what hardware is underneath.
VDCs prove that with software consistency managing the abstraction, almost any hardware can run almost any workload—today or tomorrow. They deliver the flexibility multi-site IT needs with the operational simplicity it demands.
Real-World Benefits for Multi-Site IT Teams
The combination of hardware flexibility and software consistency through VDCs translates into measurable improvements across multi-site operations. These benefits compound as organizations scale from dozens to hundreds of locations.
- Faster deployment – With hardware constraints removed, IT can bring new sites online using whatever servers are available. A retail chain opening seasonal locations can source equipment locally and have sites operational in days instead of weeks. Emergency deployments also become possible when any compatible hardware can run the workloads.
- Lower operational costs – Sites run on appropriately sized hardware instead of oversized standard configurations. Older equipment continues to generate value at smaller locations, rather than being discarded or left idle. Staff productivity rises when technicians can manage any site with familiar procedures and interfaces. Staff expertise transfers directly from one site to another—knowledge gained at headquarters applies equally at the smallest ROBO.
- Stronger disaster recovery – When hardware fails at a remote site, the VDC activates on available systems elsewhere within hours. Recovery time objectives that once stretched into days or weeks shrink to hours. Disaster recovery stops being a technical exercise and becomes a core business capability, protecting revenue and operations while lowering recovery costs.
- Reduced risk – Supply chain disruptions no longer halt deployments when alternatives exist. Single points of failure vanish as workloads move between sites. Vendor lock-in disappears when the same software runs on any hardware. Compliance strengthens when identical policies apply everywhere.
- Sustainable scalability – Adding the tenth site takes the same effort as adding the first. Management overhead stays flat as site counts grow, with each new location inheriting proven configurations and policies automatically. Growth becomes sustainable, predictable, and operationally efficient.
- Financial impact – The savings become clear when organizations measure the cost of delays, downtime, and inefficiency under traditional approaches. Hardware freedom paired with software consistency transforms multi-site IT from a cost center into a growth enabler.
Together, these benefits create a multiplier effect. Each advantage reinforces the others, building momentum as organizations expand their multi-site footprint. The result is IT that adapts to the business instead of constraining it.
Why VergeOS
The combination of hardware freedom and software consistency is not theoretical—it’s what VergeOS was built to deliver. As a single infrastructure operating system, VergeOS abstracts away hardware differences, enforces consistent policies across every site, and encapsulates each location as a Virtual Data Center. This enables deployment on any x86 server hardware, allowing for the management of Edge, ROBO, Venues, and the core using identical tools and processes. VergeOS turns the challenge of multi-site IT into a unified, predictable system.
| Aspect | Single Infrastructure OS | Multiple Software Stacks |
|---|---|---|
| Management Interface | One console for all sites | Different interfaces per platform |
| Staff Expertise | Deep knowledge in one system | Shallow knowledge across many systems |
| Training Requirements | Single curriculum | Multiple certifications needed |
| Policy Enforcement | Uniform across all locations | Manual configuration per site |
| Monitoring & Alerts | Unified dashboard | Multiple consoles to check |
| Backup Procedures | Integrated, Identical processes everywhere | Site-specific procedures |
| Security Updates | Single patch process, Virtual Labs | Different update methods per platform |
| Troubleshooting | Consistent diagnostic approach | Platform-specific expertise required |
| Documentation | Universal procedures | Site-specific manuals |
| Compliance Reporting | Centralized visibility | Manual aggregation from multiple sources |
| Disaster Recovery | Standardized failover process | Different recovery procedures per site |
| Configuration Drift | Prevented by central policies | Inevitable without coordination |
| New Site Deployment | Template-based rollout | Custom configuration each time |
| Vendor Support | Single relationship | Multiple support contracts |
| Staff Mobility | Work confidently at any site | Retraining needed per location |
| Scaling Complexity | Linear growth | Exponential complexity increase |
Conclusion
Multi-site IT can thrive if organizations stop fighting hardware diversity and start embracing it. Conventional wisdom locked IT into rigid hardware standards and fragmented software stacks. The result was procurement delays, mismatched resources, and operational sprawl. The better path reverses these priorities completely.
With VergeOS, Edge, ROBO, Venues, and the core operate as a single, consistent, unified environment leveraging disparate hardware.
George Crump is the Chief Marketing Officer at VergeIO, the leader in Ultraconverged Infrastructure. Prior to VergeIO he was Chief Product Strategist at StorONE. Before assuming roles with innovative technology vendors, George spent almost 14 years as the founder and lead analyst at Storage Switzerland. In his spare time, he continues to write blogs on Storage Switzerland to educate IT professionals on all aspects of data center storage. He is the primary contributor to Storage Switzerland and is a heavily sought-after public speaker. With over 30 years of experience designing storage solutions for data centers across the US, he has seen the birth of such technologies as RAID, NAS, SAN, Virtualization, Cloud, and Enterprise Flash. Before founding Storage Switzerland, he was CTO at one of the nation's largest storage integrators, where he was in charge of technology testing, integration, and product selection.
