Due to its fragmented state, maximizing ROI in infrastructure automation is difficult to achieve and maintain over time. Teams invest in automation with clear expectations for learning Terraform, Ansible, and Packer to build modules and playbooks that deploy infrastructure through code rather than manual procedures. The promise is speed, consistency, and operational efficiency through a straightforward ROI calculation.
Key Takeaways
Infrastructure automation ROI reverses when maintenance costs exceed time savings. Organizations invest three months learning Terraform, Ansible, and Packer with clear expectations of operational efficiency gains. Initial deployments deliver dramatic improvements as manual four-hour tasks complete in twenty minutes. By year five, however, organizations discover they have spent more total time maintaining automation than they saved through it as storage refresh, network updates, and multi-site complexity force constant code rewrites.
The hidden maintenance burden emerges during infrastructure changes that automation was supposed to handle gracefully. Storage refresh breaks Terraform modules when new arrays arrive with changed APIs and authentication patterns. Network equipment updates force Ansible role rewrites for new switch generations. Multi-site deployments maintain separate code paths for each vendor combination. Teams spend six weeks on storage refresh updates in year three, add four weeks for network updates in year four, creating maintenance cycles that consume engineering time every three to five years.
Fragmented infrastructure forces automation to inherit platform-specific complexity that compounds over time. Organizations running Dell storage, HPE networking, and mixed hypervisors maintain separate Terraform providers, vendor-specific Ansible collections, and platform-dependent monitoring exporters. Each infrastructure layer exposes different APIs that change between product generations and firmware versions. Technical debt accumulates as code grows conditional logic detecting equipment models and firmware versions, transforming automation frameworks into catalogs of platform-specific exceptions.
Unified infrastructure platforms eliminate maintenance burden through architectural abstraction that shields automation from hardware changes. Platforms integrating storage, compute, and networking into one operating system with one API allow Terraform modules to reference infrastructure services rather than hardware. Storage refresh happens through server replacement without code updates. Network changes occur transparently below the abstraction layer. The same modules and playbooks work across production running new NVMe drives and DR sites running three-year-old SATA SSDs because the platform abstracts hardware differences.
The learning investment for unified platforms is smaller because teams learn one API model instead of separate interfaces for storage, network, and hypervisor management. Organizations reach productivity faster when Terraform uses one provider, Ansible roles reference consistent APIs, and Packer templates build images without storage-backend-specific drivers. The initial three-month automation investment continues delivering value without proportional maintenance burden as teams focus on new capabilities rather than compatibility updates for hardware generations.
Infrastructure automation ROI depends more on substrate architecture than automation tool selection. Organizations can build excellent Terraform modules and well-structured Ansible playbooks, but if those tools interact with fragmented infrastructure across multiple vendor platforms, the maintenance burden will eventually exceed time savings. The strategic decision is whether to automate on fragmented infrastructure requiring constant maintenance or unified infrastructure that preserves automation investments across hardware refresh cycles spanning decades.

The reality disappoints when organizations discover they spend more time maintaining automation than they save. Promised efficiency gains evaporate as infrastructure changes trigger constant updates. Hardware refresh cycles break modules, while new storage arrays require code rewrites and additional sites multiply complexity. The automation framework becomes another system demanding constant attention rather than a tool that reduces operational burden.
The problem is not the automation tools themselves but rather that automation built on fragmented infrastructure inherits that fragmentation. When the substrate changes, the automation code must change with it, reversing the ROI calculation that looked compelling during initial planning as maintenance costs compound over time.
Key Terms & Concepts
Infrastructure Automation ROI: The return on investment calculation comparing time spent building and maintaining infrastructure-as-code against time saved through automated deployments. Initial calculations appear positive when manual four-hour deployments drop to twenty minutes, but ROI reverses when maintenance burden from infrastructure changes exceeds cumulative time savings over five-year cycles.
Maintenance Burden: The ongoing time investment required to update automation code when underlying infrastructure changes. Includes rewriting Terraform modules for new storage firmware, updating Ansible roles for changed authentication patterns, and adapting playbooks for new network equipment. Maintenance burden often exceeds initial automation development investment in fragmented infrastructure environments.
Fragmented Infrastructure: An architecture where storage arrays, network switches, and hypervisors operate as separate systems with independent APIs and management interfaces. Automation built on fragmented infrastructure inherits platform-specific complexity, requiring separate code paths for each vendor combination and firmware generation, causing maintenance costs to compound over time.
Infrastructure-as-Code (IaC): The practice of managing infrastructure through declarative configuration files and code rather than manual procedures. IaC enables version control, automated deployments, and consistent environments. Tools include Terraform for provisioning, Ansible for configuration, and Packer for image creation. ROI depends heavily on whether the underlying infrastructure supports or resists code stability.
Substrate Architecture: The foundational infrastructure layer that automation tools interact with, including storage systems, network equipment, and compute platforms. Substrate architecture determines whether automation remains stable across hardware refresh cycles or requires constant updates. Fragmented substrates force code maintenance while unified substrates preserve automation investments through abstraction.
Terraform: A HashiCorp infrastructure-as-code tool that provisions infrastructure through declarative configuration. Terraform modules define resources using provider-specific APIs. Storage refresh breaks modules when new arrays expose different endpoints. Unified infrastructure simplifies Terraform by providing one consistent provider instead of coordinating separate providers for storage, network, and compute layers.
Ansible: A configuration management tool that automates software installation and system configuration through playbooks and roles. Ansible configures hundreds of systems identically through idempotent tasks. Hardware changes break playbooks when authentication mechanisms shift or API capabilities change between equipment generations. Unified platforms reduce Ansible complexity through consistent service APIs.
Packer: A HashiCorp tool for creating identical machine images from single source configurations. Packer builds golden images containing operating systems and pre-installed software. Storage refresh complicates Packer when new arrays require different guest drivers or storage-backend-specific configurations. Unified platforms simplify image creation by presenting consistent interfaces across all hardware.
Unified Infrastructure Operating System: A platform architecture integrating storage, compute, and networking into one operating system with one API. Automation references infrastructure services rather than separate hardware components. Storage refresh happens through server replacement without code updates. Network changes occur transparently. VergeOS exemplifies this approach by eliminating external arrays and distributed switch complexity.
Technical Debt Accumulation: The growing complexity in automation code caused by infrastructure fragmentation. Each refresh cycle adds conditional logic detecting firmware versions, vendor-specific handlers for authentication changes, and platform-specific exception paths. Technical debt compounds exponentially in multi-vendor environments where storage, network, and compute layers each introduce independent maintenance requirements every three to five years.
The Known Upfront Investment
Organizations understand automation requires upfront investment as teams learn infrastructure-as-code principles and tool-specific syntax. Terraform demands understanding of providers, resources, state management, and module composition, while Ansible requires knowledge of playbooks, roles, inventory structures, and idempotency patterns. Packer needs templating logic and provisioner integration, but represents a smaller investment because its scope is narrower.

The learning curve is documented and predictable through training courses, comprehensive documentation, and supportive online communities. Organizations budget time for education and initial development, where a competent infrastructure engineer becomes productive with Terraform within weeks and proficient within months, with Ansible following a similar timeline.
Initial module development takes longer than expected but remains manageable as teams convert manual procedures into code, build libraries of reusable components, and establish version control workflows. The first production deployment validates the investment when provisioning time drops from hours to minutes, configuration drift decreases, and documentation accuracy improves because the code itself describes the infrastructure.
The upfront costs are visible, budgeted, and generally accepted by leadership, who approve the investment based on projected time savings. The business case assumes that automation, once built, will continue delivering value with minimal ongoing maintenance.
The Promised Time Savings
The automation value proposition centers on operational efficiency by eliminating the burden of manual infrastructure provisioning that consumes administrator time through repetitive tasks. Console clicks accumulate while configuration files require manual editing, and documentation lags behind actual implementation, leading to errors that introduce remediation cycles that extend deployment timelines.
Automation eliminates this burden as Terraform modules provision complete environments with a single command, Ansible playbooks configure hundreds of systems identically, and Packer builds consistent images that reduce post-deployment work. The time savings appear immediately during the first automated deployment while extending beyond speed into capabilities that manual processes cannot support.

Self-service infrastructure becomes feasible as development teams provision test environments without waiting for operations. Disaster recovery testing happens regularly because environment recreation is automated, and capacity planning improves through predictable deployment patterns.
Organizations calculate ROI by comparing pre-automation deployment times with post-automation times, where a manual deployment that took 4 hours now completes in 20 minutes with Terraform. An Ansible playbook configures 50 servers in the time it previously took to configure five manually, with numbers that convincingly justify the upfront investment.
The Hidden Maintenance Costs
The ROI calculation breaks down when infrastructure changes, such as when organizations refresh storage arrays, upgrade network equipment, add new data centers, or migrate between platforms. Each change triggers automation maintenance, consuming the time savings automation was supposed to deliver.
Storage refresh demonstrates the problem clearly:
- Production runs on three-year-old arrays while new hardware arrives with different firmware
- API endpoints change between storage generations despite staying within the same vendor
- Terraform providers lag behind firmware releases, breaking existing modules
- Authentication patterns shift from token-based to OAuth or CSRF flows
- Teams rewrite code that worked perfectly because the platform changed underneath
Multi-site deployments multiply the problem when each location runs different hardware due to refresh timing or budget constraints. Production uses vendor A, while the DR site uses vendor B, and branch offices use vendor C, forcing the automation framework to maintain separate code paths for each platform. Teams cannot deploy identical infrastructure across sites because the underlying substrates differ.
Network equipment creates similar challenges as switch models expose different management interfaces, and firmware updates change API behavior. A site refresh from one switch generation to another forces Ansible role updates even when staying within the same vendor family, causing the automation code to accumulate conditional logic that detects equipment models and branches accordingly.
When Maintenance Exceeds Savings
Organizations track time spent on automation maintenance separately from time spent building initial automation, watching the maintenance category grow steadily:
- Storage refresh: 2 weeks of Terraform updates
- Network equipment changes: 1 week of Ansible modifications
- New site deployments: 3 weeks adapting modules to different hardware
- Pattern repeats every 3-5 years across storage, network, and server refresh cycles
Teams measure actual time savings against total time invested:
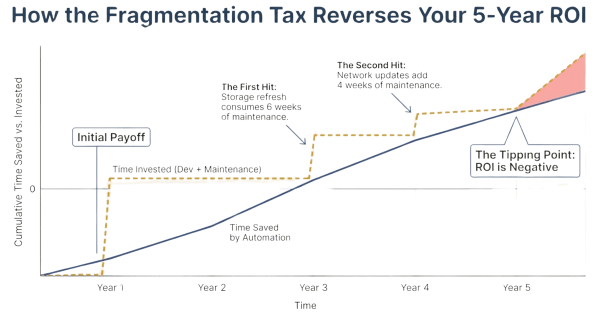
- Year 1: Initial 3-month development delivers significant time savings
- Year 2: Savings maintained with occasional updates
- Year 3: Storage refresh consumes 6 weeks of maintenance effort
- Year 4: Network updates add 4 weeks
- Year 5: Total time on automation exceeds time saved through it
The calculation worsens in multi-vendor environments where organizations running Dell storage, HPE networking, and mixed hypervisor platforms maintain separate automation branches for each vendor combination. A change in any component triggers updates across the entire stack, causing the maintenance burden to grow exponentially rather than linearly.
The Unified Infrastructure Alternative

Unified infrastructure operating systems change the ROI equation by eliminating the substrate variables that cause maintenance burden. These platforms integrate storage, compute, and networking into a single operating system with a single API, where automation interacts with infrastructure services rather than separate hardware components.
The learning curve still exists as teams learn how the unified platform exposes infrastructure services and understand how to reference storage, networking, and compute through consistent APIs. The difference is scope: instead of learning separate APIs for storage arrays, network switches, and hypervisor management, teams know a single platform model.
The learning investment is smaller because the surface area is smaller. Terraform modules reference infrastructure services through a single provider rather than coordinating separate providers for storage, networking, and compute. Ansible roles configure systems through consistent APIs rather than detecting hardware and branching accordingly, while Packer templates build images without storage-backend-specific drivers because the platform provides consistent interfaces.
Organizations achieve greater productivity when teams use learning platforms like VergeOS that automate storage provisioning, network configuration, and VM deployment via a single API model. The knowledge transfers across all infrastructure functions because the platform architecture remains consistent.
How Abstraction Preserves ROI

The ROI advantage occurs during infrastructure changes when storage refreshes occur through hardware replacement without automated updates. New servers join the cluster as the platform absorbs them into the storage pool, allowing Terraform modules to continue working without modification because they reference storage services rather than storage hardware.
Network changes follow the same pattern as switch upgrades, with automation handling them transparently. The platform handles network implementation while providing consistent constructs to Terraform and Ansible, enabling teams to refresh networking equipment without updating code, since the automation layer never interacts with network hardware directly.
Multi-site deployments simplify dramatically when production runs on new servers, the DR site runs on three-year-old hardware, and test environments use whatever equipment is available. The same Terraform modules and Ansible playbooks work at all locations because the platform abstracts hardware differences, allowing organizations to add new sites by deploying the platform and running existing automation without modifications.
Organizations seeking to build end-to-end automation chains find that a unified infrastructure maintains automation stability across the entire lifecycle, from image creation through deployment to ongoing configuration management. The time savings from the initial automation investment remain stable across years, even in year three, when storage refresh updates do not consume six weeks because storage refresh does not trigger automation maintenance. Year four does not require network equipment updates because network changes happen below the abstraction layer, while year five maintains the same operational efficiency as year one.
Organizations measure total time invested against total time saved and find that the initial three-month automation development delivers ongoing value without proportional maintenance burden. Teams spend time on new capabilities rather than updating existing code for infrastructure compatibility, keeping the ROI calculation positive under unified platforms, where it would reverse under traditional infrastructure.
VergeOS as a Unified Infrastructure Example
VergeOS demonstrates how a unified infrastructure architecture preserves automation ROI by integrating storage, compute, and networking into a single operating system. The platform eliminates external storage arrays by running storage as a distributed service across commodity servers using SATA and NVMe SSDs, removing the vendor-specific array APIs that cause maintenance burden in traditional environments.
Organizations implementing VergeOS for automated infrastructure write Terraform modules that reference a single API rather than coordinating separate providers for storage arrays, network switches, and hypervisors. A single VDC resource encapsulates compute capacity, storage performance requirements, network topologies, and protection policies, simplifying infrastructure definitions that would require dozens of separate resource blocks in fragmented environments.
The platform maintains automation stability across hardware refresh cycles through architectural abstraction. When organizations add new servers with different drive types or replace aging hardware with current-generation equipment, VergeOS absorbs these changes at the platform level while maintaining unchanged APIs for Terraform and Ansible. The same modules that provision infrastructure on three-year-old servers work identically on new hardware because automation references storage services rather than physical devices.
Multi-site deployments particularly benefit from this architecture as production data centers running modern NVMe-equipped servers use identical Terraform modules and Ansible playbooks as DR sites operating on repurposed hardware with SATA drives. Organizations refresh sites on independent schedules without maintaining separate automation branches per location, eliminating the code path multiplication that creates an exponential maintenance burden in multi-vendor environments.
The platform’s integration extends to monitoring and observability, where a single Prometheus exporter provides metrics for storage capacity, compute utilization, network throughput, and protection status through consistent schemas. Grafana dashboards displaying infrastructure performance remain unchanged across hardware refresh cycles because the platform exposes unified metrics regardless of underlying server vendors or drive generations.
This architectural approach transforms the ROI equation by preserving the initial automation investment across the infrastructure’s operational lifetime. Organizations avoid the three-to-five-year maintenance cycles that consume six weeks for storage updates and four weeks for network changes, redirecting engineering time from compatibility updates toward capabilities that deliver business value.
| Aspect | Traditional Fragmented Infrastructure | Unified Infrastructure Platform |
|---|---|---|
| Initial Learning Investment | Learn separate APIs for storage, network, hypervisor. Multiple Terraform providers and Ansible collections. | Learn one platform API. Single provider, consistent patterns. Smaller learning surface. |
| Year 1 Time Savings | Significant. Manual 4-hour deployments drop to 20 minutes. Positive ROI. | Comparable savings. Similar deployment speed. Consistent performance. |
| Year 3 Maintenance Cost | Storage refresh consumes 6 weeks rewriting modules for new firmware and APIs. | No automation updates during refresh. New servers join without code changes. |
| Year 4 Maintenance Cost | Network updates require 4 weeks updating roles for new switches. Burden grows. | Network changes transparent. No updates needed. Code stable. |
| Year 5 ROI Reality | Total automation time exceeds time saved. Initial investment plus maintenance outweighs gains. | Positive ROI maintained. Initial investment delivers ongoing value without maintenance burden. |
| Multi-Site Complexity | Separate code paths per location. Different modules for each vendor combination. | Same code everywhere. Hardware abstracted. Add sites without modifications. |
| Storage Refresh Impact | Modules fail on new arrays. Authentication changes. Resource definitions differ. Rewrites required. | Modules reference services, not hardware. New drives join without updates. |
| Network Refresh Impact | Switch changes break roles. Firmware updates change APIs. Conditional logic accumulates. | Network abstraction shields automation. Switch upgrades invisible. No version detection. |
| Cross-Vendor Penalty | Vendor switches require complete reconstruction. New providers, collections, exporters. | No vendor lock-in. Replace hardware without automation changes. Service abstraction. |
| Technical Debt Accumulation | Each refresh adds conditionals, checks, handlers. Complexity grows exponentially. | Code simplifies over time. No platform exceptions. Debt decreases. |
| Ongoing Maintenance Pattern | Continuous updates every 3-5 years per layer. Rebuild for each generation. | One-time investment. Code stable across decades. Focus on capabilities, not compatibility. |
| Total 5-Year Time Investment | Initial: 3 months. Maintenance: 20+ weeks. Total exceeds savings. | Initial: 3 months. Maintenance: Minimal. ROI remains positive. |
The Strategic Decision
Infrastructure automation ROI depends more on substrate architecture than on automation tool selection. Organizations can build excellent Terraform modules and well-structured Ansible playbooks, but if those tools interact with fragmented infrastructure across storage arrays, network equipment, and hypervisor layers, the maintenance burden will eventually exceed the time savings.
Unified infrastructure platforms reduce the total cost of automation through architectural abstraction where the upfront learning investment decreases and the ongoing maintenance burden drops significantly. The time savings from automation remain stable across infrastructure lifecycle events that would otherwise trigger code updates.
The decision is not whether to automate but rather whether to automate on top of fragmented infrastructure that will require constant maintenance or on top of unified infrastructure that preserves automation investments across hardware generations.
Organizations seeking infrastructure automation ROI should evaluate the substrate as carefully as the automation tools. The tools are commodities while the infrastructure architecture determines whether automation delivers lasting value or becomes another maintenance burden that consumes more time than it saves.
Frequently Asked Questions
Why does infrastructure automation ROI reverse after the initial investment appears successful?
Initial automation delivers dramatic time savings when manual four-hour deployments drop to twenty minutes through Terraform. However, infrastructure changes trigger maintenance cycles that consume those savings. Storage refresh in year three requires six weeks rewriting modules for new firmware and changed APIs. Network updates in year four add four weeks modifying Ansible roles. By year five, organizations discover they spent more total time on automation maintenance than they saved through automated deployments because infrastructure changes repeat every three to five years.
What specific maintenance tasks consume the most time during infrastructure refresh cycles?
Storage refresh creates the largest burden through multiple simultaneous changes. API endpoints change between array generations, breaking existing Terraform modules. Authentication patterns shift from token-based to OAuth or CSRF flows, requiring updates across hundreds of Ansible playbooks. Resource definitions differ between product lines within the same vendor, forcing near-complete rewrites. Terraform providers lag behind firmware releases, extending maintenance windows. Network equipment follows similar patterns as switch model changes expose different management interfaces.
Can better planning or modular code architecture prevent automation maintenance costs from growing?
No. The problem is architectural rather than procedural. Storage arrays expose vendor-specific APIs that change between product generations regardless of code structure. Better Terraform module design cannot eliminate API incompatibility between Dell PowerStore and PowerMax or prevent HPE from splitting Primera and Nimble into separate REST schemas. Modular code reduces some duplication but cannot abstract away fundamental platform fragmentation. The substrate architecture determines maintenance burden more than automation code quality.
How does multi-vendor infrastructure affect automation maintenance compared to single-vendor standardization?
Multi-vendor environments grow maintenance burden exponentially rather than linearly. Organizations running Dell storage, HPE networking, and mixed hypervisors maintain separate Terraform providers, vendor-specific Ansible collections, and platform-dependent monitoring exporters for each combination. A change in any component triggers updates across the entire stack. However, single-vendor standardization provides limited protection because vendors operate product lines as independent platforms with incompatible APIs. Refreshing from Unity to PowerStore within Dell requires nearly as extensive rewrites as switching vendors entirely.
What is the learning curve difference between traditional fragmented infrastructure and unified platforms?
Traditional infrastructure requires learning separate APIs for storage arrays, network switches, and hypervisor management. Teams master multiple Terraform providers, vendor-specific Ansible collections, and platform-dependent patterns. Unified platforms reduce the learning surface by providing one API model where storage provisioning, network configuration, and VM deployment follow consistent patterns. Organizations reach productivity faster because knowledge transfers across all infrastructure functions instead of requiring separate expertise for each vendor platform and product line.
How do unified infrastructure platforms handle storage refresh without breaking automation?
Unified platforms integrate storage as a distributed service within the infrastructure operating system rather than as external arrays. Terraform modules reference storage services instead of hardware, remaining stable when new servers join clusters. The platform absorbs new drives into the storage pool while maintaining consistent API presentation to automation tools. Storage refresh happens through hardware replacement without triggering module updates because automation never interacts with storage hardware directly. Authentication patterns stay constant and resource definitions remain unchanged across refresh cycles.
Can existing automation transfer to unified platforms or does migration require starting from scratch?
Migration requires rewriting automation because the architectural model changes from managing separate storage arrays, network switches, and hypervisors to referencing integrated infrastructure services. However, this is a one-time rewrite that eliminates future refresh-driven maintenance entirely. The code simplifies because it no longer needs vendor detection logic, firmware version checks, or generation-specific conditionals. The automation investment becomes durable across decades of hardware refresh rather than requiring updates every three to five years when infrastructure components change.
What is the total cost comparison between maintaining fragmented infrastructure automation versus migrating to unified platforms?
Fragmented infrastructure requires initial three-month development plus ongoing maintenance consuming twenty or more weeks across five-year cycles. Storage refresh consumes six weeks, network updates add four weeks, and multi-site adaptations require three weeks each. The pattern repeats every refresh cycle. Unified platforms require similar initial development plus migration effort but eliminate ongoing refresh-driven maintenance. Organizations measure whether one-time migration investment plus minimal ongoing maintenance costs less than continuous five-year maintenance cycles repeating across infrastructure’s operational lifetime.
How should organizations evaluate whether their infrastructure substrate supports or resists automation?
Examine how infrastructure changes affect automation code. Storage refresh requiring Terraform rewrites indicates substrate resistance. Network updates forcing Ansible modifications signal fragmentation. Multi-site deployments needing separate code paths per location demonstrate substrate complexity. Count vendor-specific Terraform providers, platform-dependent Ansible collections, and conditional logic branches detecting equipment models. Higher counts indicate greater substrate resistance. Unified substrates allow the same code to work across production running new hardware and DR running old equipment without modification.
At what point should organizations consider migrating from fragmented to unified infrastructure platforms?
Natural migration windows occur during major infrastructure transitions when disruption is unavoidable. Storage refresh cycles every three to five years create opportunities. VMware exits align with infrastructure simplification decisions. Data center consolidations provide migration justification. Organizations should calculate total maintenance time invested over the past five years against projected maintenance for the next decade. If maintenance burden trends toward exceeding time savings, migration timing aligns with the next major refresh cycle when automation rewrites would occur regardless of platform choice.
George Crump is the Chief Marketing Officer at VergeIO, the leader in Ultraconverged Infrastructure. Prior to VergeIO he was Chief Product Strategist at StorONE. Before assuming roles with innovative technology vendors, George spent almost 14 years as the founder and lead analyst at Storage Switzerland. In his spare time, he continues to write blogs on Storage Switzerland to educate IT professionals on all aspects of data center storage. He is the primary contributor to Storage Switzerland and is a heavily sought-after public speaker. With over 30 years of experience designing storage solutions for data centers across the US, he has seen the birth of such technologies as RAID, NAS, SAN, Virtualization, Cloud, and Enterprise Flash. Before founding Storage Switzerland, he was CTO at one of the nation's largest storage integrators, where he was in charge of technology testing, integration, and product selection.
