
RAM and flash storage prices have increased as much as 50% since this time last year. In response, some IT planners consider reducing their protection levels, stepping down from N+2 data availability to N+1. The logic is simple: if capacity costs more, buy less of it, including less redundancy.
That logic is wrong. The value of an organization’s data has not decreased. If anything, data is more central to operations than it was a year ago. The cost of losing that data, measured in downtime, recovery effort, and business disruption, has only gone up.
Key Takeaways
| 1 | Rising flash costs are not a reason to reduce protection levels. The same AI demand driving prices up is making your data more valuable. Cutting redundancy to save on capacity is a short-term decision with long-term consequences. |
| 2 | The rebuild window is the real risk. Larger drives mean longer rebuilds, and every hour in that window exposes the environment to both data loss and performance degradation. |
| 3 | Not all N+2 methods are equal. RAID 6 and erasure coding impose performance penalties during normal operations and degrade further during failures. Triple mirroring maintains near-normal performance throughout. |
| 4 | Triple mirror rebuilds are faster because the process reads from two surviving copies in parallel. Parity-based methods reconstruct data mathematically from a single degraded stripe, which takes longer and stresses the surviving drives. |
| 5 | A repair server extends protection beyond N+2 to N+X. As long as one production server and the repair server are running, all data remains accessible without reaching for backups. |
| 6 | Commodity NVMe drives maintain a 10x price advantage over enterprise drives even after recent price increases. A triple mirror on commodity flash often costs less per terabyte than N+1 RAID on enterprise drives. |
| 7 | For most organizations, a triple mirror (N+2) combined with a repair server is the right balance of availability, performance, and cost. Organizations demanding the highest availability should consider N+3 with a repair server. |
The irony is that the same force driving storage prices higher is also making your data more valuable. AI workloads are consuming flash and memory capacity at scale, creating the supply pressure behind the price increases. But AI is also redefining what organizational data is worth. Every company will implement AI internally at some point. Many already have. When that happens, the data you are creating and storing today becomes training data, context data, and decision-support data for models that drive revenue and competitive advantage. Data that looks like a cost center today becomes a strategic asset tomorrow. Reducing the protection around that data to save on storage costs is a short-term decision with long-term consequences.
Higher storage costs do not justify lower protection. They justify smarter protection.
Key Terms
| N+1 | Protection level that sustains one simultaneous device failure without data loss. A second failure during the rebuild window results in data loss. |
| N+2 | Protection level that sustains two simultaneous device failures without data loss and without requiring recovery from backup. |
| N+X | Protection level achieved by combining a triple mirror with a repair server. As long as one production server and the repair server are running, all data remains accessible without reaching for backups. |
| Rebuild Window | The time required to return the storage infrastructure to a fully protected state after a device failure. During this window, both redundancy and performance are reduced. |
| Dual Parity RAID (RAID 6) | N+2 protection method that stripes data across multiple disks with two distributed parity blocks per stripe. Sustains two drive failures but imposes significant write penalties and performance degradation during rebuilds. |
| Erasure Coding | N+2 protection method that splits data into fragments with mathematically generated parity fragments distributed across drives or nodes. Offers capacity efficiency but adds CPU, latency, and network overhead during both normal and degraded operations. |
| Triple Mirror (RF3) | N+2 protection method that maintains three complete copies of every data block. Delivers the lowest latency of any N+2 method with minimal performance degradation during failures and faster rebuilds than parity-based approaches. |
| Repair Server | A standalone server that holds data blocks and feeds them back to the production environment during failures that exceed the primary redundancy level. Does not host VMs or handle production I/O. |
| ioGuardian | VergeOS’s repair server technology that supports both on-site and off-site repair servers, extending N+2 protection to N+X availability across sites. |
| HCI | Hyperconverged Infrastructure. A converged architecture that aggregates compute, storage, and networking from multiple servers into a shared pool. Server failures remove multiple drives simultaneously, increasing the blast radius of each failure. |
| UCI | Ultraconverged Infrastructure. A converged architecture that extends HCI by also integrating networking and data protection into a single software platform, reducing multi-vendor complexity. |
What N+2 Data Availability Means in Practice
N+2 data availability means the infrastructure sustains two simultaneous device failures without data loss, without performance collapse, and without requiring a recovery from backup. Users and applications maintain access to all data at production-level performance throughout the event.
In traditional storage arrays, “devices” means drives. Two drives fail, data stays online. Learn more about Data Availability and Disaster Recovery during VergeIO’s live webinar “Right-Sizing Disaster Recovery with VergeOS 26.1”
In converged architectures like hyperconverged infrastructure (HCI) or ultraconverged infrastructure (UCI), the definition expands. These systems aggregate internal drives from multiple servers into shared volumes. The drives depend on the servers that house them. A single server going offline takes all of its drives with it. Two servers going offline can remove dozens of drives from the pool simultaneously. As a result, converged architectures carry a greater responsibility for continuous availability because the blast radius of a single failure is larger. A failure that removes a server also removes its CPU, memory, and network capacity from the cluster, compounding the performance impact on surviving nodes.
Why the Rebuild Window Threatens N+1 Data Availability
The rebuild window is the time required to return the storage infrastructure to a fully protected state after a failure. That process involves identifying a replacement drive, installing it, and recreating the at-risk data across the remaining healthy drives. During that entire window, the environment operates in a degraded state where both redundancy and performance are reduced.
In N+1 designs, one drive failure leaves the environment exposed. A second failure during the rebuild window causes data loss. The statistical probability of two near-simultaneous failures is low, but the business impact is catastrophic. That risk calculus is what drove widespread adoption of N+2 data availability in the first place.

The problem has gotten worse over time. Drive capacities have increased dramatically over the past decade, and rebuild times have increased with them. Volumes built on 8TB or larger hard disk drives can take days or weeks to rebuild. Flash drives at 16TB and above can take double-digit hours. Every hour in that rebuild window is an hour when the environment is running at reduced redundancy and performance, and a second failure means data loss. The remaining drives handle both production I/O and data reconstruction simultaneously, forcing users and applications to compete with the rebuild process for throughput and IOPS.
N+2 protection closes the data loss exposure window, but not all N+2 methods handle the performance impact equally. Some methods impose significant overhead during normal operations and degrade further under failure conditions. Others maintain near-normal performance throughout. The question is not whether N+2 is worth the investment. The question is which N+2 method delivers protection without sacrificing the performance your workloads require.
N+2 Data Availability Methods Compared
Dual Parity RAID
Dual-parity RAID (RAID 6) is the most common form of N+2 protection. RAID 6 stripes data across multiple disks and stores two different parity blocks for each stripe, distributed across all drives in the set. If any two drives fail simultaneously, the array reconstructs the missing data from parity and stays online.
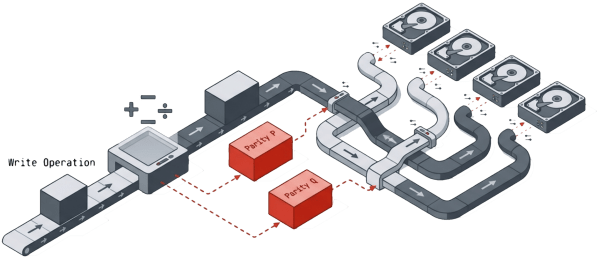
RAID 6 delivers good read performance and reasonable space efficiency under normal conditions. The tradeoff is write performance. Every small write triggers a read-modify-write cycle with dual-parity calculations, adding latency to every transaction even when all drives are healthy.
The performance picture gets worse during failures. When a drive fails, the remaining drives handle production I/O while simultaneously reconstructing parity data. Latency increases. Throughput drops. A second simultaneous failure doubles the reconstruction workload on the surviving drives. For performance-sensitive workloads like databases and virtual machines, the degradation during rebuild can be severe enough to trigger application timeouts and SLA violations. RAID 6 keeps the data available during a dual failure, but it does not keep the data fast.
Erasure Coding
Erasure coding, commonly used in Object Storage for cold archives, splits data into multiple fragments and generates additional parity fragments using mathematical algorithms. The system distributes all fragments across drives or nodes. As long as a sufficient subset of fragments remains available, the system reconstructs the original data.
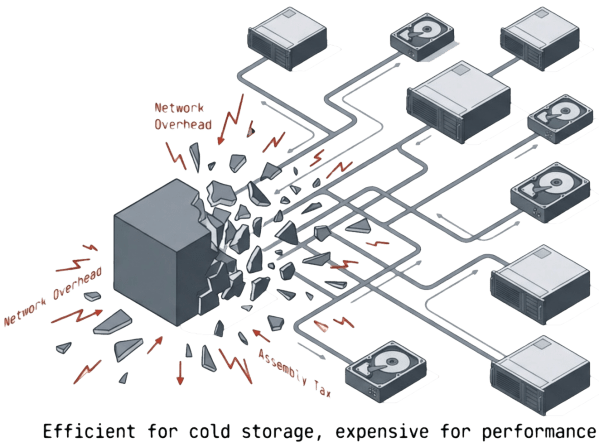
Erasure coding offers flexible fault tolerance and good capacity efficiency. The cost is performance overhead that exists at all times, not just during failures. Every read and write requires assembling multiple fragments and running encode/decode operations. Small random I/O workloads suffer the most because each operation touches multiple drives or nodes.
During failures, the performance impact compounds. Rebuilds increase internal network traffic because fragments are spread across many locations. The surviving drives and nodes handle fragment reconstruction on top of production I/O. Implementations are also more complex to design and tune than mirroring or basic RAID, and misconfiguration leads to performance problems that are difficult to diagnose. Organizations that choose erasure coding for its capacity efficiency often discover that the performance cost during both normal and degraded operations offsets the savings.
Triple Mirror (RF3)
A triple mirror keeps three complete copies of every data block on three different drives or fault domains. Any single copy can satisfy a read. If one or even two copies are lost, the remaining copy serves all requests without interruption.
Triple mirroring delivers the lowest and most predictable latency of any N+2 method, both during normal operations and during failures. Reads load-balance across all three copies, distributing I/O across more drives than parity-based methods. Writes replicate directly without parity math, eliminating the read-modify-write penalty that drags down RAID 6 and erasure coding performance.
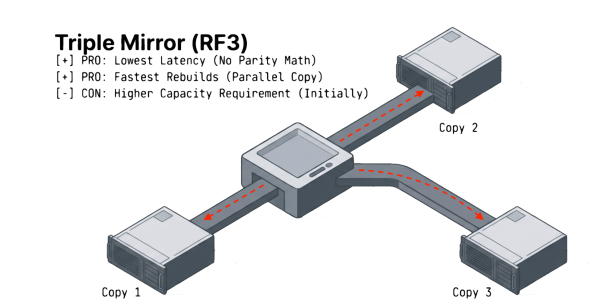
The performance advantage becomes most pronounced during failures. When a drive fails, the surviving two copies continue to serve reads at full speed. The rebuild reads from both surviving copies in parallel, shortening the exposure window compared to parity-based methods that reconstruct data mathematically from a single degraded stripe. Rebuilds are straightforward block copies from intact mirror members. The rebuild process is faster, consumes less CPU, and puts less I/O stress on the surviving drives than parity reconstructions. Users and applications experience minimal performance degradation during the rebuild window, which is when performance matters most.
The advantages are high fault tolerance, excellent performance for VM and database workloads under all conditions, and operational simplicity. The perceived disadvantage is capacity overhead. Detractors point to the 3x raw capacity requirement, but that comparison ignores the overhead of alternatives. A 100TB dataset requires approximately 133TB under RAID 5 and 150TB under RAID 6. The triple mirror requires 300TB. Compared to RAID 6, the additional overhead is roughly 100% more raw capacity, not 3x. When you factor in the performance and rebuild speed advantages, the cost per protected IOPS often favors the triple mirror.
Repair Servers: Extending N+2 Data Availability to N+X
A repair server is a standalone server separate from the primary infrastructure. It holds a copy of data blocks but does not host virtual machines or handle production I/O. In the event of a failure that exceeds the primary redundancy level, the repair server feeds missing blocks back to the production environment in real time. This covers multi-drive and even multi-server failures, which is critical in converged environments where a single server failure can remove many drives simultaneously.
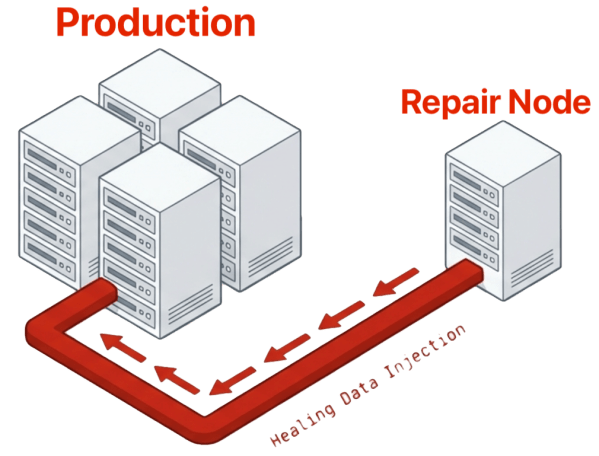
Because the repair server is dedicated to data repair, it does not compete with production workloads for resources. The primary infrastructure receives missing blocks without diverting its own CPU, memory, or drive bandwidth to reconstruction. This separation is a fundamental advantage over parity-based methods, where the same drives that serve production I/O also run the rebuild.
A repair server combined with a triple mirror delivers N+X availability, a protection level that exceeds what any standalone RAID or erasure coding implementation can match. N+X means that as long as one production server is running and the repair server is running, there is active access to all data without reaching for backups. VergeOS’s ioGuardian is an example of this approach. VergeIO extends the concept further by supporting both on-site and off-site repair servers. An off-site repair server at the DR site provides inline recovery at the cost of WAN latency, turning the disaster recovery site into an active participant in primary-site availability.
How to Lower the Cost of N+2 Data Availability
Commodity Drives Cut Per-TB Costs
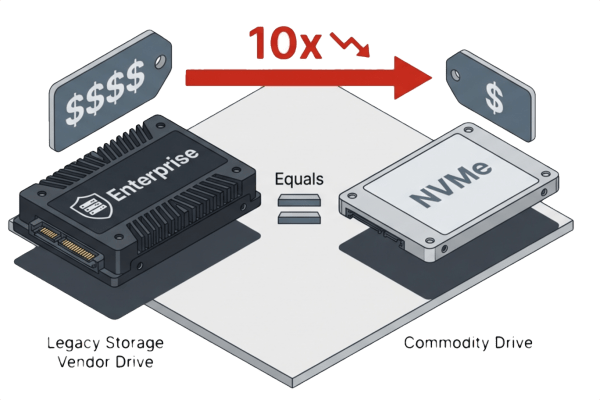
The flash price increases that concern IT planners apply to enterprise-class drives from traditional storage vendors. Commodity NVMe drives from manufacturers like Solidigm, Micron, and Samsung deliver the same capacity at a fraction of the cost, often 10x less per terabyte than drives sold through legacy storage vendors. These commodity drives have also increased in price, but not at the same pace, and they still maintain their 10x price advantage.
Organizations running converged architectures such as VergeOS on standard x86 servers can purchase commodity drives directly, avoiding the markup, but because of all the protection, maintain better availability than if they selected enterprise systems. The capacity overhead of a triple mirror on commodity flash is often less expensive per terabyte than N+1 RAID on enterprise drives. The protection level is higher, the rebuild is faster, and the performance during both normal and degraded operations is better.
Cross-Site Recovery as a Protection Layer
Disaster recovery sites represent existing infrastructure that most organizations already fund. Instead of treating the DR site as a passive standby, organizations can use it as an active protection layer.
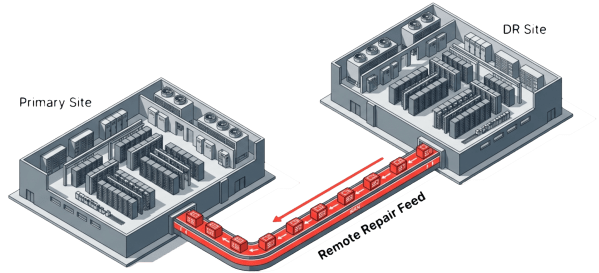
Off-site repair servers feed missing blocks to the primary site during failures, extending availability beyond what local redundancy provides. The repair traffic flows over the WAN, which adds latency compared to local repair, but the production infrastructure avoids the performance penalty of running its own rebuild. Workload encapsulation technologies like virtual data centers allow entire application stacks to restart at the DR site in minutes, not hours. If a primary-site failure exceeds local repair capacity, the DR site takes over production workloads immediately with full performance.
This approach converts disaster recovery from a cost center into an active availability resource. The DR infrastructure that organizations already pay for becomes part of the primary protection strategy, reducing the net cost of N+2 and N+X availability.
The Argument for More N+2 Data Availability, Not Less
Rising flash costs create pressure to reduce redundancy. That pressure points in the wrong direction. Data is more valuable than it was a year ago, and AI will make it more valuable still. Rebuild windows are longer than they were a decade ago. Performance degradation during those rebuilds is more disruptive than it was when drives were smaller and rebuild times were measured in minutes. Converged architectures concentrate more drives behind fewer servers than traditional arrays, amplifying both the data risk and the performance impact of every failure.
Every one of these trends argues for more protection, not less.
The path forward is not to accept more risk. It is to choose the right combination of protection method and infrastructure economics. For most organizations, a triple mirror (N+2) combined with a repair server delivers the right balance of availability, performance, and cost. The triple mirror maintains production-level performance during failures. The repair server extends protection to N+X, covering scenarios that exceed standard redundancy. For organizations that demand the highest level of availability, a triple mirror with an additional copy (N+3) combined with a repair server provides protection that no parity-based method can approach.
Commodity drives on converged infrastructure make both configurations more affordable than most IT planners assume. The cost of protecting data is going down. The cost of losing it is going up. The decision should be straightforward.
Frequently Asked Questions
| Why not just drop to N+1 protection to save money on flash? |
| N+1 leaves the environment exposed the moment a single drive fails. A second failure during the rebuild window causes data loss. With drive capacities increasing and rebuild times stretching into hours or days, that exposure window is longer than it has ever been. The cost of data loss far exceeds the cost of maintaining N+2 protection, especially when commodity drives and converged architectures can bring the per-terabyte cost down. |
| What is the difference between N+2 and N+X availability? |
| N+2 means the infrastructure sustains two simultaneous device failures without data loss. N+X goes further by adding a repair server that feeds missing data blocks back to the production environment in real time. With N+X, as long as one production server and the repair server are running, all data remains accessible without reaching for backups, even during multi-drive or multi-server failures. |
| Why does a triple mirror rebuild faster than RAID 6 or erasure coding? |
| A triple mirror rebuild reads from two surviving copies of the data in parallel and writes straightforward block copies to the replacement drive. RAID 6 and erasure coding reconstruct missing data mathematically from parity, which requires more CPU, more I/O operations per block, and more stress on the surviving drives. The triple mirror approach is faster, consumes less compute, and causes less performance degradation during the rebuild. |
| Doesn’t a triple mirror require three times the capacity? |
| The 3x number is misleading because it ignores the overhead of alternatives. A 100TB dataset requires approximately 133TB under RAID 5 and 150TB under RAID 6. The triple mirror requires 300TB. Compared to RAID 6, the additional overhead is roughly 100% more raw capacity, not 3x. When commodity NVMe drives cost 10x less per terabyte than enterprise drives, a triple mirror on commodity flash often costs less than N+1 RAID on enterprise drives with better performance and faster rebuilds. |
| What is a repair server and how does it differ from a failover server? |
| A repair server is a standalone server that holds copies of data blocks but does not host virtual machines or handle production I/O. Its only job is to feed missing blocks back to the production infrastructure during failures. A failover server takes over production workloads when the primary server goes down. A repair server keeps the primary infrastructure running by supplying the data it needs to heal itself, without the cost and complexity of maintaining a full failover environment. |
| Can a repair server work across sites? |
| Yes. VergeOS’s ioGuardian supports both on-site and off-site repair servers. An off-site repair server at the DR site provides inline recovery at the cost of WAN latency. This turns the disaster recovery site into an active participant in primary-site availability rather than a passive standby. If a primary-site failure exceeds local repair capacity, workload encapsulation allows entire application stacks to restart at the DR site in minutes. |
| How do rising flash prices relate to AI? |
| AI workloads are consuming flash and memory capacity at scale, creating the supply pressure behind the price increases. At the same time, AI is making organizational data more valuable. The data you store today will become training data, context data, and decision-support data for AI models that drive revenue and competitive advantage. The same force raising storage costs is raising the cost of losing that data. |
| What protection level do you recommend? |
| For most organizations, a triple mirror (N+2) combined with a repair server delivers the right balance of availability, performance, and cost. The triple mirror maintains production-level performance during failures while the repair server extends protection to N+X. Organizations that demand the highest level of availability should consider a triple mirror with an additional copy (N+3) combined with a repair server, which provides protection that no parity-based method can approach. |
George Crump is the Chief Marketing Officer at VergeIO, the leader in Ultraconverged Infrastructure. Prior to VergeIO he was Chief Product Strategist at StorONE. Before assuming roles with innovative technology vendors, George spent almost 14 years as the founder and lead analyst at Storage Switzerland. In his spare time, he continues to write blogs on Storage Switzerland to educate IT professionals on all aspects of data center storage. He is the primary contributor to Storage Switzerland and is a heavily sought-after public speaker. With over 30 years of experience designing storage solutions for data centers across the US, he has seen the birth of such technologies as RAID, NAS, SAN, Virtualization, Cloud, and Enterprise Flash. Before founding Storage Switzerland, he was CTO at one of the nation's largest storage integrators, where he was in charge of technology testing, integration, and product selection.
