Big Data Analytics uses distributed computing architectures, on platforms like Hadoop, to run large processing jobs on even larger datasets. Since data being processed in a Hadoop environment usually needs to be resident on the compute nodes themselves, this can mean copying large numbers of files across the network for each job run. HDS has combined the power of scale-out storage, deterministic networking and server virtualization to address these storage challenges. And as a hyper-converged appliance, the Hitachi Hyper Scale-Out Platform (HSP) is easy to set up and run, making these distributed compute infrastructures a better fit for the enterprise.
No Science Project
Big Data infrastructures often resemble science projects with IT organizations struggling to integrate the various components necessary to make the system work. As a converged clusterable appliance, HSP includes everything needed to create a high-speed compute or analytics environment. Designed for easy implementation users can get set up and running in a few minutes and the system can discover new nodes automatically. And now, with HDS’ acquisition of analytics platform developer Pentaho, HSP users can more easily stand up a Big Data project with the confidence that it won’t become a do-it-yourself headache.
The Distributed Computing Problem
Distributed computing platforms, such as Hadoop, tackle very big compute jobs by parsing them into smaller jobs and running those on multiple compute engines. This “divide and conquer” approach allows big projects to be processed in parallel, greatly accelerating the time to results. 
But in order to support this distributed architecture the data sets for each of these compute engines are often copied from another source to local storage, usually hard drives in the scale-out compute node itself. This is an inefficient way to manage data, especially when the files used for these compute jobs are sent over the local network. Further, data normally residing in HDFS (Hadoop File System) cannot be shared with other non-Hadoop applications. HDS solves this problem logically and physically, with the HSP.
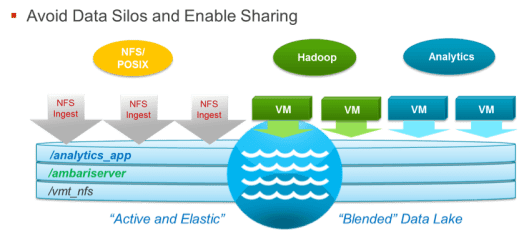
The Hyper-converged Scale-out Answer
Hyper-converged systems are ideal for distributed computing. They merge the compute function with the storage function, add server virtualization and make the entire infrastructure simpler to set up and manage. This architecture also supports the use of commodity hardware, enabling companies to save money on storage and compute capacity. But there needs to be a way to reduce the data movement that’s traditionally inherent with distributed computing, and make it more efficient, even when these environments are supported by scale-out storage systems.
Each HSP cluster provides a scale-out file server with a POSIX-compliant, distributed file system that puts all the files into a shared storage pool (aka “Data Lake”) and makes them logically available to every compute node in the cluster. This allows applications to access data directly, without moving or copying it from a central repository to the particular node that’s going to do a given piece of work. HSP nodes run Linux and come with a built-in virtual machine manager, able to run any application that runs in a kernel-based KVM compute environment.
Using a scale-out storage architecture, HSP physically disperses data among the nodes in the cluster. This enables data to be processed where it resides (see “Data-in-Place Processing” below) and reduces the need to move large amounts of data across a storage network. HSP also leverages the power of high-speed inter-node connections to move data within the cluster. Each node has dual-port connectivity to a 40GbE network running through two Brocade top-of-rack switches.

HDS Hyper Scale-Out Platform
HSP System Hardware
Hitachi Hyper Scale-Out Platform, model 400, has been architected to scale up to 1000’s of nodes. The base orderable system consists of a 5-node configuration, expanding in 1-node increments to 100 nodes (as tested to date) as it grows. Each 2U node includes two Intel Xeon processors, 192 GB of memory, 8GB of NVRAM and twelve 3.5” 6TB 7200RPM NL-SAS disk drives, or 2.5” 800G SSD drives, in the very near future. Each node has redundant power supplies, a dual-port, 40GbE QSFP NIC for back-end connectivity between nodes and a dual-port, 10GbE SFP NIC for front-end connectivity with host systems.
Brocade Switching
Internet routing is inherently variable so IP switching was historically designed to route packets asynchronously, based on current network traffic and congestion and resend those that fail in transmission. This “probabilistic” design improved network reliability but added latency.
In contrast, fibre channel storage networks, are “deterministic” in nature. They assume a reliable network with consistent routing and so can be designed without the limitations of IP switching, producing lower latency. The HSP cluster includes a Brocade ICX 7750 Top-of-Rack switch that was purpose built for this use case. Its deterministic design with a non-blocking architecture provides the ideal network for a scale-out topology.
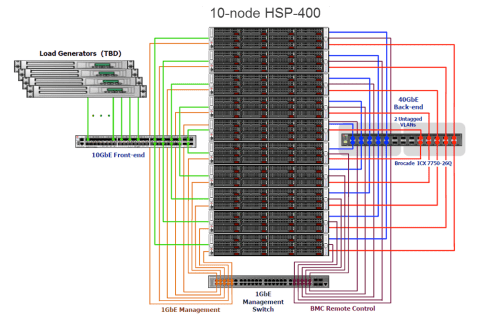
Hyper-converged architectures can be extremely scalable and flexible, but only if the internal network doesn’t become a bottleneck as they increase capacity and performance. Brocade ensures this by providing consistently low latency and more than enough bandwidth to handle any level of inter-node traffic the system can generate.
Resilient, Scale-out Architecture
As a scale-out system, HSP provides the ability to start small (5 nodes and a few hundred TBs) and grow into the multiple petabytes without impacting performance, since each node contains CPU and memory as well as storage capacity. Data is automatically copied (using a synchronous, three-copy policy), thin provisioned and distributed across the scale-out cluster of nodes to ensure high availability and data resiliency. This fault-tolerant design enables the system to “self-heal”, automatically failing over and rebuilding disk drives or nodes, even recovering from a failed rack using other copies of data.
Traditional Hadoop architectures use a single Master or NameNode to control the distribution of processing jobs to individual Slave nodes in the system. This architecture can create a metadata bottleneck that can impact performance. HDS’ global file system architecture also distributes the metadata along with the file data, allowing every node to serve files and eliminate the inefficiency of centralized metadata management.
Data-in-Place Processing
In a traditional Hadoop environment compute nodes have local storage capacity, which is used to hold the datasets that are copied in from a centralized pool. In a hyper-converged architecture, the same nodes that run the compute engines also comprise the scale-out storage cluster. So if the data needed for a particular compute job was already located on a particular node, this would eliminate much of the data movement.
HSP has intelligence in the system to understand where specific data sets reside allowing local compute resources to be applied to those jobs. And since the compute engines themselves are run as virtual machines, the system can simply start VMs on the nodes that contain the associated data sets. This means the right analytics applications running on the right VMs can be deployed in the right numbers to maximize performance, remove data movement latency and minimize time to results.
This data-in-place processing leverages server virtualization to make compute resources completely dynamic, enabling them to be configured or defined as needed, and then redefined when those needs change. This results in better overall performance as data movement is minimized and all available compute resources are applied to jobs at hand.
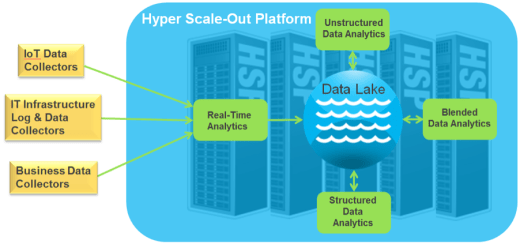
High-speed Data Ingest
HSP’s distributed architecture enables multi-stream data ingest, reducing the time required to get large datasets into the environment. Many Big Data applications include a significant amount of pre-processing, involving normalization and conversion to make datasets comparable. Here again, by combining storage capacity and compute power in the same physical nodes, this conversion can be done on ingest, keeping data movement to a minimum.
As a virtual server platform, the system can start VMs supporting the appropriate processing applications, and as many instances as required to optimize this operation. The ingest process generates files of multiple types, all feeding a common repository, called a “data lake”, that’s managed by HSP’s scale-out file server. Once in this global file system, the HSP can run analytics jobs on widely diverse data sets that comprise the data lake, simplifying the workflow and enabling better results. More uniquely, whether data is in VM containers, or Hadoop, or mounted via NFS, it is all sharable. Data does not have to be copied between VMs or Hadoop clusters to be processed, They simply reside on the distributed file system.
Post-Analytics
Part of the challenge for enterprises running Big Data Analytics applications is managing the results after the analysis has been run. As a POSIX-compliant file server, HSP can store and access results as easily as it does raw data and make it available for further analysis, using the distributed compute infrastructure or traditional database applications. There is also an archive connector to facilitate longer-term storage of data and providing regulatory compliance.
StorageSwiss Take
It seems like all the big problems in IT manifest themselves in storage, so it’s no surprise that many of Big Data’s problems show up as storage problems too. A distributed computing infrastructure, which most big analytics applications use, creates a challenge for storage as data is continually moved between compute nodes and a central repository. And let’s face it, data is only getting bigger.
A hyper-converged architecture would seem ideal for these distributed computing challenges, but needs the global file system and high-speed inter-node connectivity that Hitachi’s HSP provides. HDS bundles the whole solution as a scale-out appliance, with built-in server virtualization to solve the storage challenges created by distributed compute environments like Hadoop, and make Big Data analytics fit easily into the enterprise IT environment. And with Hitachi’s reputation for reliability and quality, users can avoid do-it-yourself infrastructure projects and get quickly to what is really important: business insight.
This independently developed document is sponsored by HDS. The document may utilize publicly available material from various vendors, including HDS, but it does not necessarily reflect the positions of such vendors on the issues addressed in this document.
George Crump is the Chief Marketing Officer at VergeIO, the leader in Ultraconverged Infrastructure. Prior to VergeIO he was Chief Product Strategist at StorONE. Before assuming roles with innovative technology vendors, George spent almost 14 years as the founder and lead analyst at Storage Switzerland. In his spare time, he continues to write blogs on Storage Switzerland to educate IT professionals on all aspects of data center storage. He is the primary contributor to Storage Switzerland and is a heavily sought-after public speaker. With over 30 years of experience designing storage solutions for data centers across the US, he has seen the birth of such technologies as RAID, NAS, SAN, Virtualization, Cloud, and Enterprise Flash. Before founding Storage Switzerland, he was CTO at one of the nation's largest storage integrators, where he was in charge of technology testing, integration, and product selection.
