Hypervisor deduplication has a storage efficiency problem that most buyers don’t discover until after deployment. For years, the overhead it creates was hiding in plain sight — organizations focused on RAM consumption, licensing costs, and hardware compatibility while storage overhead quietly consumed capacity that was never accounted for. In 2026, with enterprise SSD pricing up 472 percent year over year, that gap has a dollar figure. And for most organizations running legacy hypervisor architectures, it is substantial.
The problem is not just that legacy platforms consume more storage than necessary. It is that the way they consume it — through optional, per-volume, off-by-default deduplication — creates a cascading inefficiency that extends from disk all the way into RAM cache. Understanding that chain is the first step to eliminating it.
Key Takeaways
- Legacy hypervisors treat deduplication as an optional feature — frequently disabled for performance-sensitive workloads and run on a per-volume basis, which fragments efficiency across the environment.
- Many HCI vendors specifically recommend disabling deduplication when using advanced data protection such as erasure coding or RF3, leaving organizations paying full price for every redundant block.
- Per-volume deduplication is architecturally limited — data that is identical across two volumes remains two copies in storage and two copies in cache, because the deduplication algorithm has no visibility across volume boundaries.
- The RAM cache penalty is compounding: when a VM on volume 1 and a VM on volume 2 both request the same data block, the system must cache it twice — even though the block is logically identical.
- The solution requires deduplication integrated into the full stack — not just storage, but compute, networking, caching, and data protection — running from a single code base.
How Hypervisor Deduplication Actually Works — and Where It Fails
Most enterprise hyperconverged platforms market deduplication as a storage efficiency feature. It is real — when it runs. The fine print is in three places that most buyers miss until they are already deployed.

Third, even when deduplication is enabled, it operates at the volume boundary. Data that is identical across two separate volumes — the same OS image, the same application binaries, the same patch set deployed across a fleet of VMs — exists as two distinct copies in storage if those VMs live on different volumes. The deduplication algorithm has no visibility across volume lines. The efficiency gain is at best partial, and in environments where VMs are distributed across multiple pools or storage policies, it may be negligible.
Key Terms
Per-Volume Deduplication
A deduplication model where the system identifies and consolidates duplicate data blocks only within a single storage volume or pool. Data that is identical across two volumes remains as two separate copies — the algorithm has no cross-volume visibility.
Global Deduplication
A deduplication model that operates across the entire storage environment — all volumes, all nodes, all VMs — from a single unified data store. One copy of any unique block exists, regardless of how many virtual machines reference it or which node it runs on.
Write Amplification
The ratio of actual data written to storage relative to the logical data written by the application. Advanced data protection schemes like erasure coding and RF3 increase write amplification because each logical write triggers multiple physical writes to maintain redundant copies.
Cache Poisoning
In per-volume storage architectures, the condition where logically identical data blocks occupy multiple cache slots because the caching layer has no cross-volume deduplication. Cache capacity is consumed by redundant copies of the same data, reducing effective cache size for unique data.
The RAM Cache Problem Nobody Talks About
The storage inefficiency is visible and measurable. The RAM cache inefficiency is less obvious and equally expensive.
Most modern HCI platforms use a tiered caching model: frequently accessed data is promoted from persistent storage into RAM cache, where it can be served at memory speeds rather than SSD speeds. The cache is a finite resource — typically a portion of the server’s installed RAM, which at current DDR5 pricing represents a significant capital investment on its own.
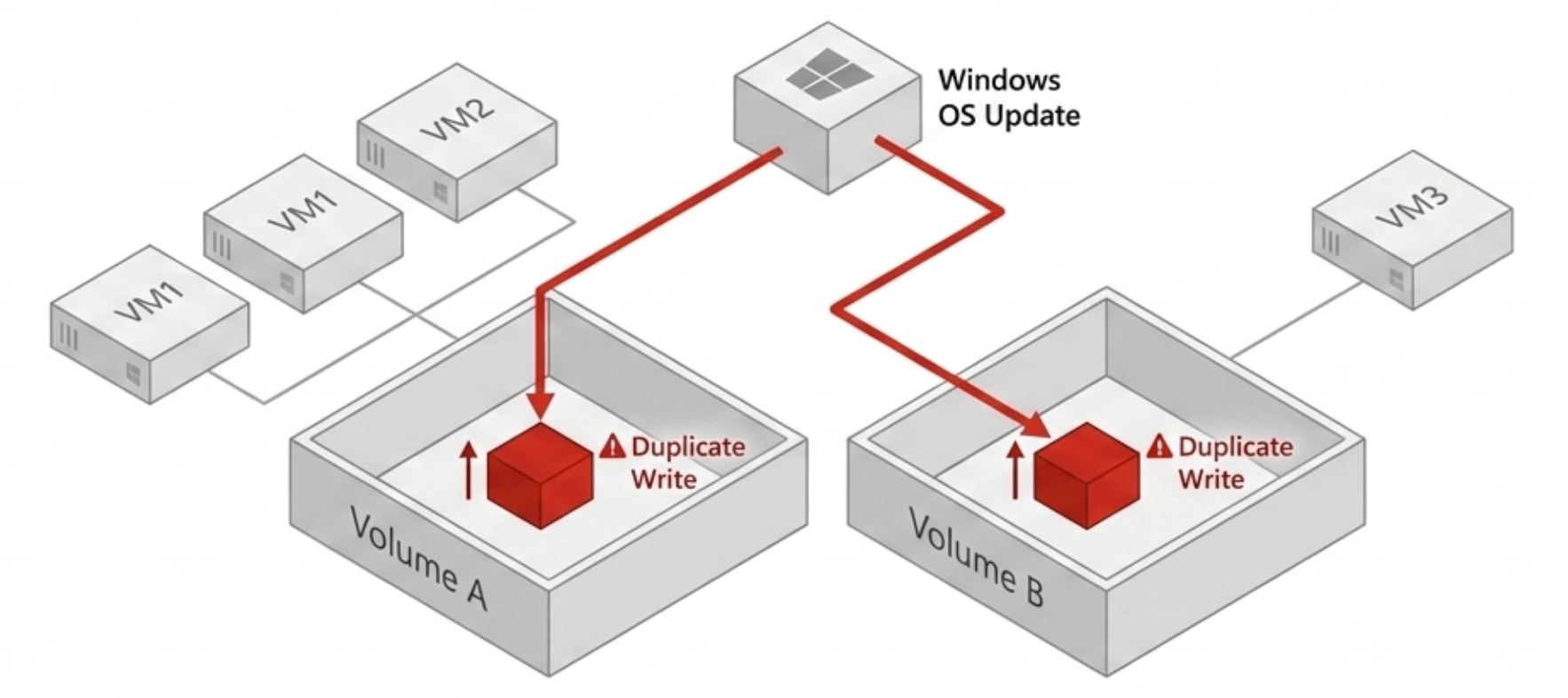
This effect scales with the degree of commonality across VMs. Environments running large fleets of identically configured VMs — VDI deployments, containerized workloads, standardized server images — have the most in common across their VM population and therefore the worst cache efficiency in a per-volume architecture. The more uniform the environment, the more cache capacity is wasted on redundant copies of shared data.
Why Advanced Protection Makes It Worse
The cache problem and the deduplication trade-off converge most acutely in environments that use advanced data protection.
|
RF3 and erasure coding provide stronger data durability guarantees than standard two-copy protection. They are appropriate choices for environments with zero tolerance for data loss, for archival data, and for high-value production workloads. But they come at a cost: more write amplification, more storage capacity consumed per logical unit of data, and — on platforms that recommend disabling deduplication under these configurations — the complete elimination of whatever storage efficiency the platform would otherwise deliver. An organization running RF3 without deduplication is paying three times the raw storage cost for every unique block — and then paying full price again for every duplicate block, because the deduplication that would have consolidated them has been disabled. The same organization is running a cache layer that is filling up with redundant copies of shared data, reducing effective cache capacity and driving more reads to storage — storage already consuming three times the physical capacity per logical byte. |
TruthInIT Webinar · April 30
The New Economics of VMware Exit
George Crump and Mike Matchett unpack the hardware ambush, the flash supply squeeze, the deduplication trap, and the exit math that actually works in 2026. Live Q&A included. Register Now → |
This is not a corner case. It is the recommended configuration for a significant portion of production workloads on the most popular HCI platforms.
The Integrated Architecture Answer
The problem has a structural cause — deduplication implemented as a storage feature rather than as a foundational property of the entire stack. The solution requires the same structural response.
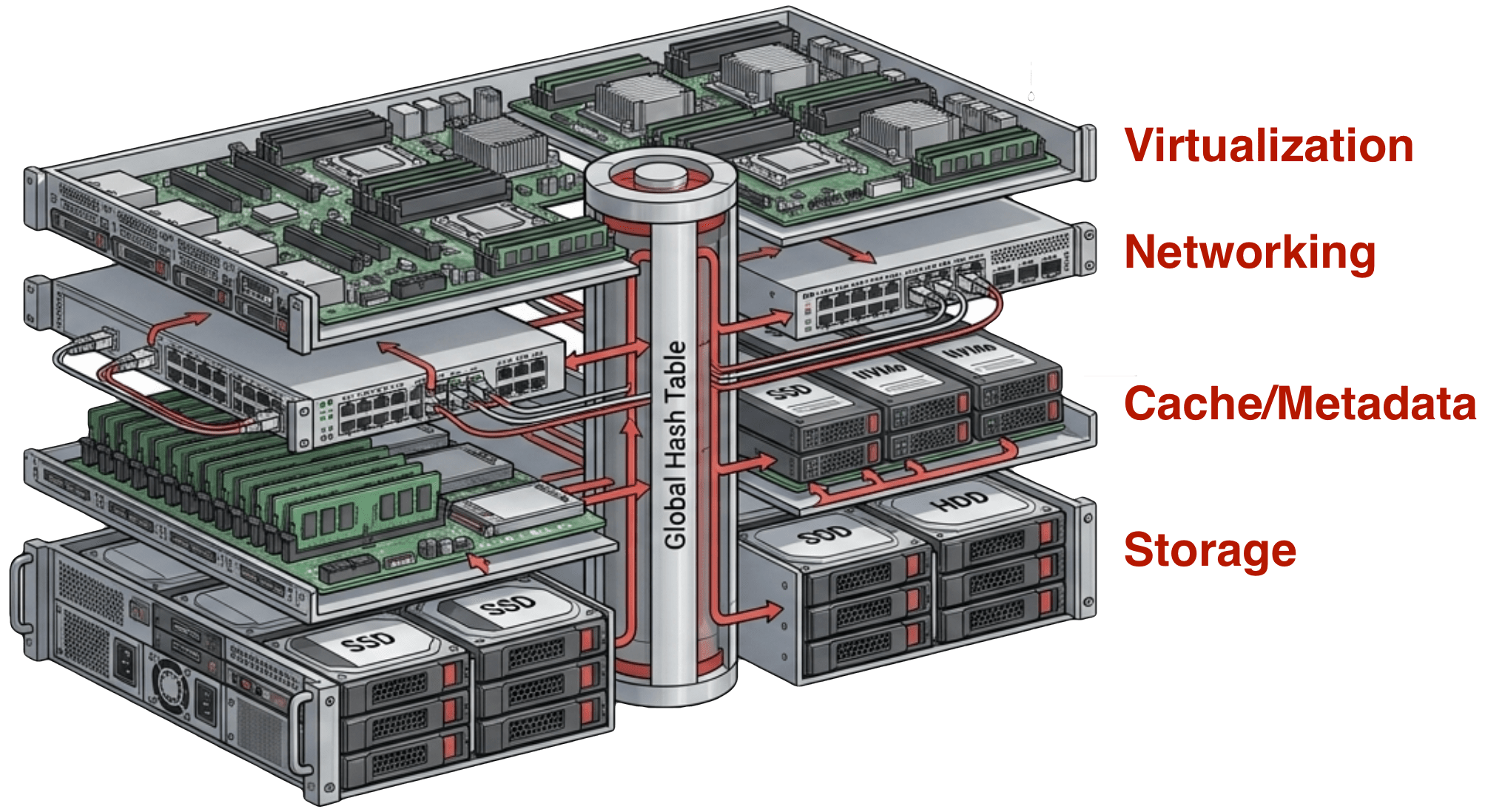
VergeOS is built on this model. The entire platform — hypervisor, storage, networking, data protection — runs from a single integrated code base. Deduplication is not a storage feature that can be toggled off. It is the architecture. The result in production environments is that a continuous 3:1 or better hypervisor deduplication ratio applies across the entire environment at all times, regardless of data protection configuration. Cache operates on deduplicated block references. RAM capacity serves unique data. The hidden storage tax that per-volume architectures impose across storage and cache simultaneously does not exist in the first place.
Counting the Cost
At current enterprise SSD pricing of approximately $100 per terabyte, the storage efficiency gap between a globally deduplicated platform and a per-volume platform on a typical enterprise VM workload translates to tens of thousands of dollars per cluster in raw flash capacity. The cache efficiency gap adds another layer — reduced cache hit rates mean more I/O to storage, shorter effective SSD lifespan, and degraded application performance that eventually requires hardware upgrades to restore.
The storage tax in legacy hypervisors has always been in place. In 2026, the price per percentage point of wasted capacity finally makes it visible.
Frequently Asked Questions
Why do HCI vendors recommend turning off deduplication for erasure coding or RF3?
Because on platforms where deduplication is a background process separate from the write path, running both simultaneously creates competing I/O workloads. The deduplication process reads and rewrites data blocks while the data protection layer is already amplifying writes for redundancy. The vendor recommendation is to choose one, and in production, protection usually wins.
How much cache capacity is lost to per-volume duplicate copies?
It depends on how much data is shared across VMs. In standardized environments — VDI, containerized workloads, large fleets of identically configured servers — the commonality across VMs can be very high. A significant portion of cache can be consumed by duplicate copies of OS images, application binaries, and shared datasets that a globally deduplicated system would hold as a single reference.
Does VergeOS maintain deduplication under RF3 and advanced data protection?
Yes. Because deduplication is integrated into the write path rather than implemented as a background process, there is no conflict between protection and efficiency. Data protection maintains redundant copies of unique deduplicated blocks — not redundant copies of duplicate blocks. The 3:1 or better ratio applies regardless of the protection configuration.
What workloads benefit most from global deduplication?
Environments with high VM commonality see the largest gains: VDI deployments, large fleets of standardized server images, containerized workloads, and test/dev environments with many clones of the same base image. These are also the environments where per-volume deduplication delivers the least, because the shared data spans volume boundaries rather than a single pool.
George Crump is the Chief Marketing Officer at VergeIO, the leader in Ultraconverged Infrastructure. Prior to VergeIO he was Chief Product Strategist at StorONE. Before assuming roles with innovative technology vendors, George spent almost 14 years as the founder and lead analyst at Storage Switzerland. In his spare time, he continues to write blogs on Storage Switzerland to educate IT professionals on all aspects of data center storage. He is the primary contributor to Storage Switzerland and is a heavily sought-after public speaker. With over 30 years of experience designing storage solutions for data centers across the US, he has seen the birth of such technologies as RAID, NAS, SAN, Virtualization, Cloud, and Enterprise Flash. Before founding Storage Switzerland, he was CTO at one of the nation's largest storage integrators, where he was in charge of technology testing, integration, and product selection.
