A recent VergeIO article focuses on the future requirements of an AI-ready exit. The VMware alternative near-future requirements deserve equal attention. Future-proofing is not only about supporting the next generation of workloads. It is about building an architecture where multiple generations of technology coexist and deliver value together.
Key Takeaways
- A VMware alternative has near-future requirements, not just the AI readiness that gets most of the attention.
- Flash and memory pricing is unlikely to return to its historical decline, so existing hardware needs to keep earning its place.
- Standing up a new infrastructure island for every workload adds hardware, tools, and specialists the economics no longer support.
- The right platform lets multiple generations of hardware operate as one system.
- VergeOS integrates compute, storage, and networking in one code base and supports a node-at-a-time refresh.
For years, infrastructure planning ran on a predictable cycle. New servers replaced old servers, new storage replaced old storage, and each refresh promised better performance at a lower cost. Organizations could retire aging equipment and start fresh. Those assumptions no longer hold. Server costs keep climbing, flash pricing remains under pressure, and AI demand has intensified competition for memory, accelerators, and storage media.
Key Terms
Future-Proofing
Building an architecture where multiple generations of technology coexist and deliver value together, rather than supporting only the next generation of workloads.
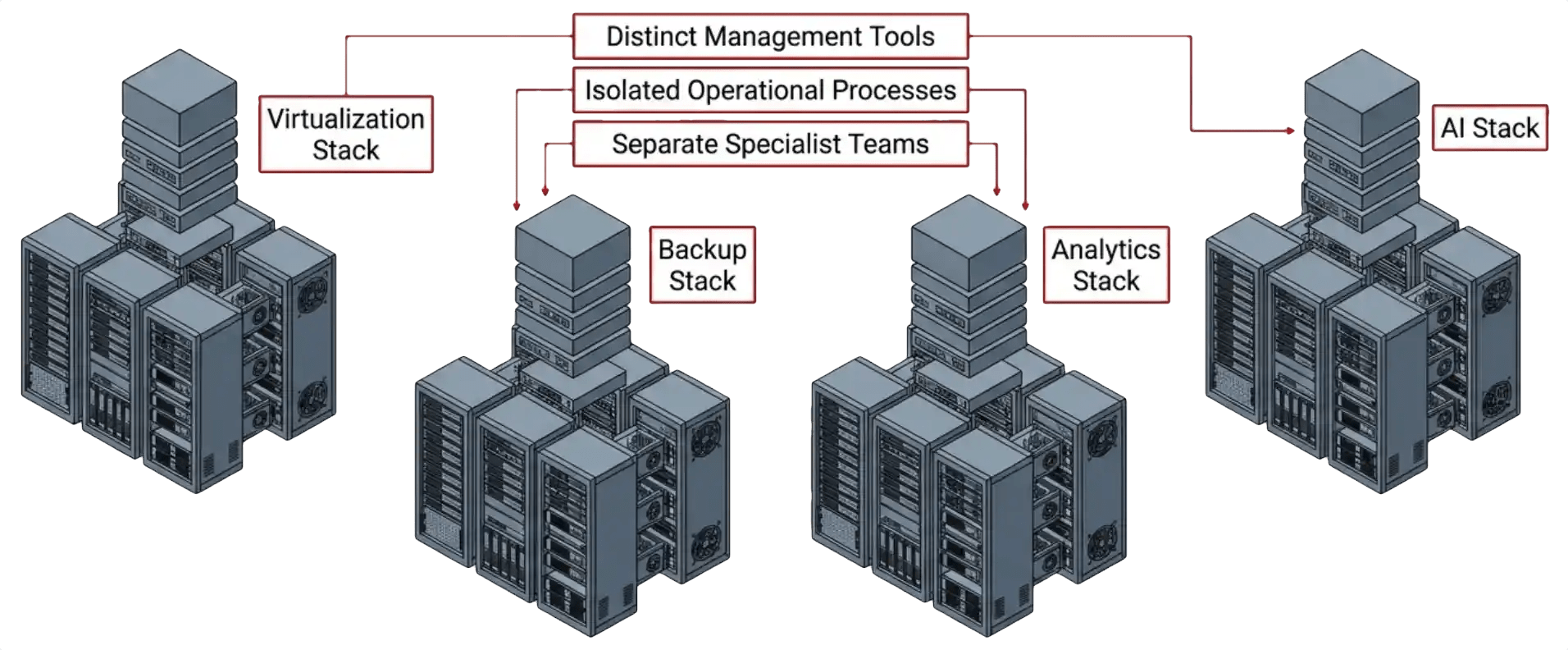
Infrastructure Island
A separate hardware and software stack stood up for each new requirement, such as virtualization, backup, analytics, or AI. Each island adds its own tools, processes, and specialists.
Node-at-a-Time Refresh
Replacing hardware one server at a time on your own schedule, draining workloads off an aging node before retiring it, without a disruptive migration event.
Forklift Upgrade
Wholesale replacement of an environment in a single migration, the model that periodic refresh cycles traditionally required.
At the same time, much of the existing infrastructure remains more than capable of running current business applications. Most enterprise workloads are not constrained by processor performance, and many applications already have more storage performance available than they can consume. The problem has shifted. The challenge is no longer finding more performance. It is extracting more value from the existing performance.
Capacity Growth Is the One Constant
One assumption from the last decade survives intact: data continues to grow. Organizations still struggle to delete anything, retention requirements keep expanding, and AI has turned historical data into a strategic asset worth keeping. Many analysts expect flash and memory pricing to resume its historical decline by 2030. I do not share that view. AI has created a new class of demand for memory, flash, and accelerators, and supply cannot keep up. Prices will fluctuate, but the long-term trend will be shaped by persistent demand rather than persistent oversupply.
That reality changes how infrastructure should be designed. Performance requirements continue to climb for a select group of workloads, particularly AI and analytics, but capacity requirements are rising for nearly everything. The traditional response was to stand up a new infrastructure island whenever a new requirement appeared, and that response is the heart of the problem.
The Hidden Cost of Building Another Island
The industry spent twenty years solving new problems by standing up new architectures. Virtualization got its own stack. Backup got its own stack. Analytics often got its own stack. AI is now pressing for yet another. Each stack adds hardware, management tools, operational processes, and frequently a new set of specialists. When hardware was cheap and refresh cycles were short, that pattern was easy to justify. The economics have flipped. Hardware stays productive longer, acquisition costs keep rising, and capacity demand keeps growing. Building another island now means paying more for hardware that should have stayed in service and paying again for the people and tools to run a separate environment.
A VMware Alternative Has Near-Future Requirements
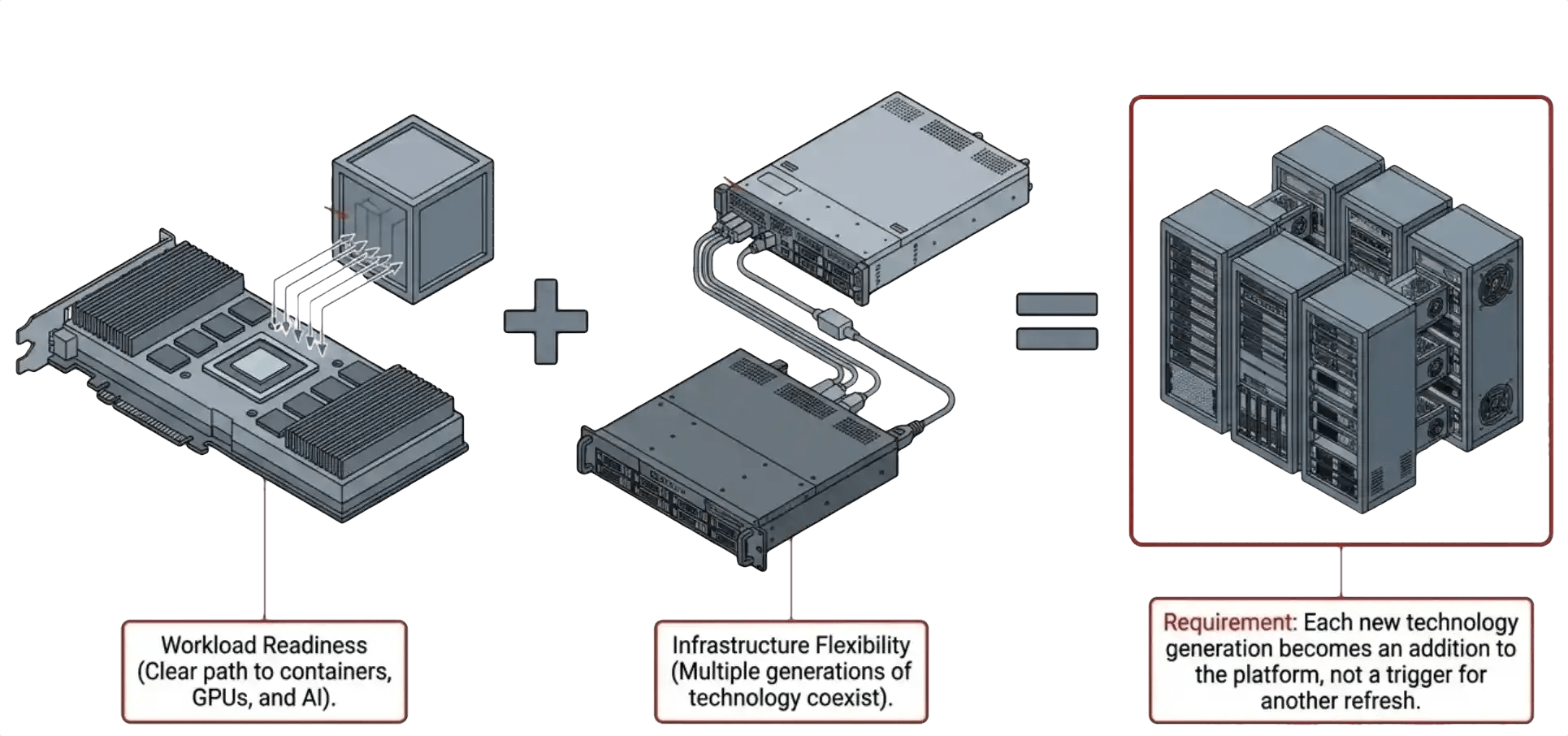
The VergeIO article makes a strong case that organizations should judge a VMware alternative on its ability to support future workloads. A platform chosen today should offer a clear path to containers, GPUs, AI applications, and whatever comes next. Workload readiness is only half of the future-proofing equation. The other half is infrastructure flexibility, the set of near-future requirements that determine how long today’s hardware keeps paying off.
Organizations should be able to introduce new technology without discarding productive hardware. New GPU-equipped servers should run alongside existing compute. New processor generations should complement older systems rather than obsolete them. New storage should extend capacity and performance where needed without forcing a wholesale replacement of equipment that still works. The goal is not stretching hardware life for its own sake. The goal is an environment where each new technology generation becomes an addition to the platform rather than a trigger for another refresh.
The Economics of a Successful VMware Exit
For most of the past twenty years, infrastructure teams could justify periodic forklift upgrades. New generations delivered enough improvement to offset the cost and disruption of migration. That math no longer works the way it used to. The useful life of many components now runs past the traditional refresh window. Processor performance has outpaced the needs of most enterprise applications, and flash performance routinely exceeds the demands of those workloads. Replacement costs, meanwhile, keep climbing.
The ability to fold multiple generations of technology into one operating model now matters as much as support for future workloads. Organizations that combine existing infrastructure with new investment gain a real financial advantage. They can allocate capital to areas that drive differentiation, including AI initiatives, GPU resources, and advanced analytics, rather than repeatedly replacing infrastructure that still delivers value.
VergeOS as the Example
VergeOS shows what this second form of future-proofing looks like in practice. The product integrates compute, storage, and networking into a single code base rather than assembling separate hypervisor, storage, and network products into a stack. That design choice is what lets multiple generations of hardware operate as one system.
A VergeOS environment treats every server, old or new, as a contributor to a shared pool of resources. An organization can add GPU-equipped nodes for AI work and run them in the same cluster as the older servers handling routine business applications. The software-defined storage layer pools the drives across those nodes, so a newer all-flash server and an older hybrid server feed the same data store. Capacity and performance extend across generations rather than fracturing into separate tiers that each demand their own management.
The migration model reinforces the point. VergeOS supports a node-at-a-time refresh. An organization replaces hardware on its own schedule, drains workloads off an aging server, retires it, and brings a new one online without a forklift event. Existing equipment continues to earn its place in the cluster until it no longer makes financial sense to run. New equipment joins without disrupting what already runs.
This approach answers both halves of the future-proofing question at once. VergeOS runs the containers, GPUs, and AI workloads that define workload readiness, and it does so on an architecture in which existing servers, storage, and networking continue to deliver value. The result is one platform and one operating model, rather than an expanding collection of islands, all of which significantly improves ROI as the VergeIO infrastructure calculator shows.
Two Questions Every VMware Exit Should Answer
Organizations evaluating a VMware alternative tend to focus on the immediate problem of licensing cost and platform replacement. Those objectives matter, but they should not be the only forces driving the decision. The first question is straightforward. What workloads will the organization need to support over the next five years? The second question carries even more weight. What platform will let the organization keep extracting value from existing infrastructure as it adopts new technology?
A successful VMware exit answers both. The platform should open a path to AI, containers, GPUs, and future application architectures. It should also create an operating model where multiple generations of infrastructure coexist and contribute. Organizations that achieve both adopt innovation without falling into a cycle of continuous replacement.
Conclusion
A VMware exit is a chance to rethink more than software licensing. The question is no longer whether a platform can support AI, since most vendors will meet that bar eventually. The harder question is whether an organization can support AI without building another island that consumes more capital, operational effort, and expertise. The VMware alternative near-future requirements come down to one thing: supporting new workloads without abandoning productive infrastructure. VergeOS is built to do both, which is why it deserves a close look in any VMware exit evaluation.
Frequently Asked Questions
What are the near-future requirements of a VMware alternative?
Beyond replacing the hypervisor and supporting future workloads, a VMware alternative should let existing servers, storage, and networking keep contributing value as new technology arrives. Near-future requirements cover the flexibility to run multiple hardware generations in one operating model.
Will flash and memory prices return to their historical decline?
That outcome is unlikely. AI has created a new class of demand for memory, flash, and accelerators, and supply cannot keep up. Prices will fluctuate, but the long-term trend will be shaped by persistent demand rather than persistent oversupply.
What is an infrastructure island, and why is it a problem?
An infrastructure island is a separate stack built for each new requirement. Each one adds hardware, management tools, operational processes, and often new specialists. With acquisition costs rising and equipment staying productive longer, the cost of another island is harder to justify.
How does VergeOS meet these near-future requirements?
VergeOS integrates compute, storage, and networking in one code base, so multiple hardware generations operate as one system. Organizations add GPU nodes for AI alongside older servers, pool storage across both, and refresh one node at a time without a forklift event.
George Crump is the Chief Marketing Officer at VergeIO, the leader in Ultraconverged Infrastructure. Prior to VergeIO he was Chief Product Strategist at StorONE. Before assuming roles with innovative technology vendors, George spent almost 14 years as the founder and lead analyst at Storage Switzerland. In his spare time, he continues to write blogs on Storage Switzerland to educate IT professionals on all aspects of data center storage. He is the primary contributor to Storage Switzerland and is a heavily sought-after public speaker. With over 30 years of experience designing storage solutions for data centers across the US, he has seen the birth of such technologies as RAID, NAS, SAN, Virtualization, Cloud, and Enterprise Flash. Before founding Storage Switzerland, he was CTO at one of the nation's largest storage integrators, where he was in charge of technology testing, integration, and product selection.
