Containers disappear by design. The workload does not. That distinction sits at the center of nearly every Kubernetes recovery failure. Development teams describe containers as ephemeral, and from the perspective of the container image and pod lifecycle, they are correct. The image is immutable. The pod is disposable. Kubernetes restarts failed instances and reschedules workloads across the cluster without operator involvement. The abstraction changed how teams deploy and scale applications.
Key Takeaways
- Pod ephemerality is a developer abstraction, not an operational reality. The workload outlives the pod.
- Six categories of state survive pod restart and die with the cluster: configuration, identity, scheduling intent, network identity, operator lifecycle, and audit history.
- Etcd holds the relationships between workloads, policies, identities, and orchestration metadata. CSI snapshots do not protect any of it.
- Every protection boundary introduces a consistency boundary. Fragmented protection means components captured at different points in time.
- GitOps preserves desired state, not operational state. Runtime secrets, generated certificates, and operator state never enter source control.
- The recovery drill — restoring a workload end-to-end to a fresh cluster — is the test that surfaces what was actually protected.
The abstraction also created operational confusion. Many infrastructure teams carried the idea of ephemerality into the protection conversation and concluded that Kubernetes workloads do not require backup. The first generation of Kubernetes operators treated redeployment from source control as a recovery strategy. The second generation recognized persistent storage and began snapshotting Persistent Volume Claims through CSI. Both approaches solve only part of the problem.
Key Terms
Workload
Everything required to reconstitute a running Kubernetes application on a clean cluster. Includes pods, persistent volumes, configuration, secrets, identities, network rules, and operator-managed custom resources.
CSI Snapshot
A point-in-time copy of a persistent volume’s data state, taken by the Container Storage Interface driver. Stored where the driver decides, usually on the same storage backend as primary.
Etcd
The distributed key-value store that holds Kubernetes control plane state. Secrets, ConfigMaps, Services, CRDs, RBAC relationships, namespace state, and deployment metadata all live here. The cluster loses operational identity when etcd disappears.
Application-Consistent Backup
A backup taken with the running application quiesced so that in-flight writes are flushed and the data on disk represents a coherent application state. Distinct from crash-consistent, which captures whatever happens to be on disk at the moment.
Operator
A controller that watches custom resources and reconciles the running cluster state against the desired state described by those resources. The operator’s intent lives in the CRD. Without that intent, the operator does not know what to manage.
Recovery Drill
A scheduled exercise in which a production workload is restored to a fresh cluster from backup, verified for correctness, and timed. The test that distinguishes backup ownership from recovery capability.
The pod is ephemeral. The workload is persistent. A production workload includes every component required to reconstruct the running application on a clean cluster. Persistent data matters, though configuration, identity, networking, scheduling policies, operator state, and recovery metadata matter just as much. Most of those objects live inside the Kubernetes API, not inside the container image and not inside the storage volume. Recovering storage without recovering operational state produces an application that exists but does not function.
When the Ephemeral Model Holds
Some Kubernetes workloads genuinely are disposable. Batch processing pipelines, CI runners, transcoding engines, queue consumers, and AI training jobs often fit the original container model precisely. The container starts, performs a task, writes output to another system, and terminates. State enters from one persistent platform and exits through another. Nothing important remains inside the pod.
In these environments, protecting the external systems protects the workload. The storage platform hosting the database matters. The object repository storing artifacts matters. The message broker matters. The container itself does not.
That model works cleanly for stateless execution layers. The problem begins when infrastructure teams generalize the model to applications that carry operational state inside the Kubernetes control plane.
Where the Ephemeral Model Breaks
Most production Kubernetes applications present themselves as stateless during normal operation and expose their statefulness during recovery. A web service storing TLS certificates inside Kubernetes Secrets is stateful. A microservice controlled by ConfigMaps and Helm values is stateful. A PostgreSQL operator managing topology, scaling policy, replication configuration, and backup orchestration through Custom Resource Definitions is deeply stateful.
The storage volume contains only part of the application. The Kubernetes API contains the rest. Restoring the persistent volume without restoring the Kubernetes objects produces a workload with data but no operational identity. The database files return, though the operator no longer understands the topology. The application container starts, though the Service object exposing the workload never returns. The pod launches, though the Secrets required for authentication disappeared with the cluster.
The line separating ephemeral from persistent does not sit at the pod boundary. It sits at the workload boundary.
The Six Layers of State Most Teams Miss
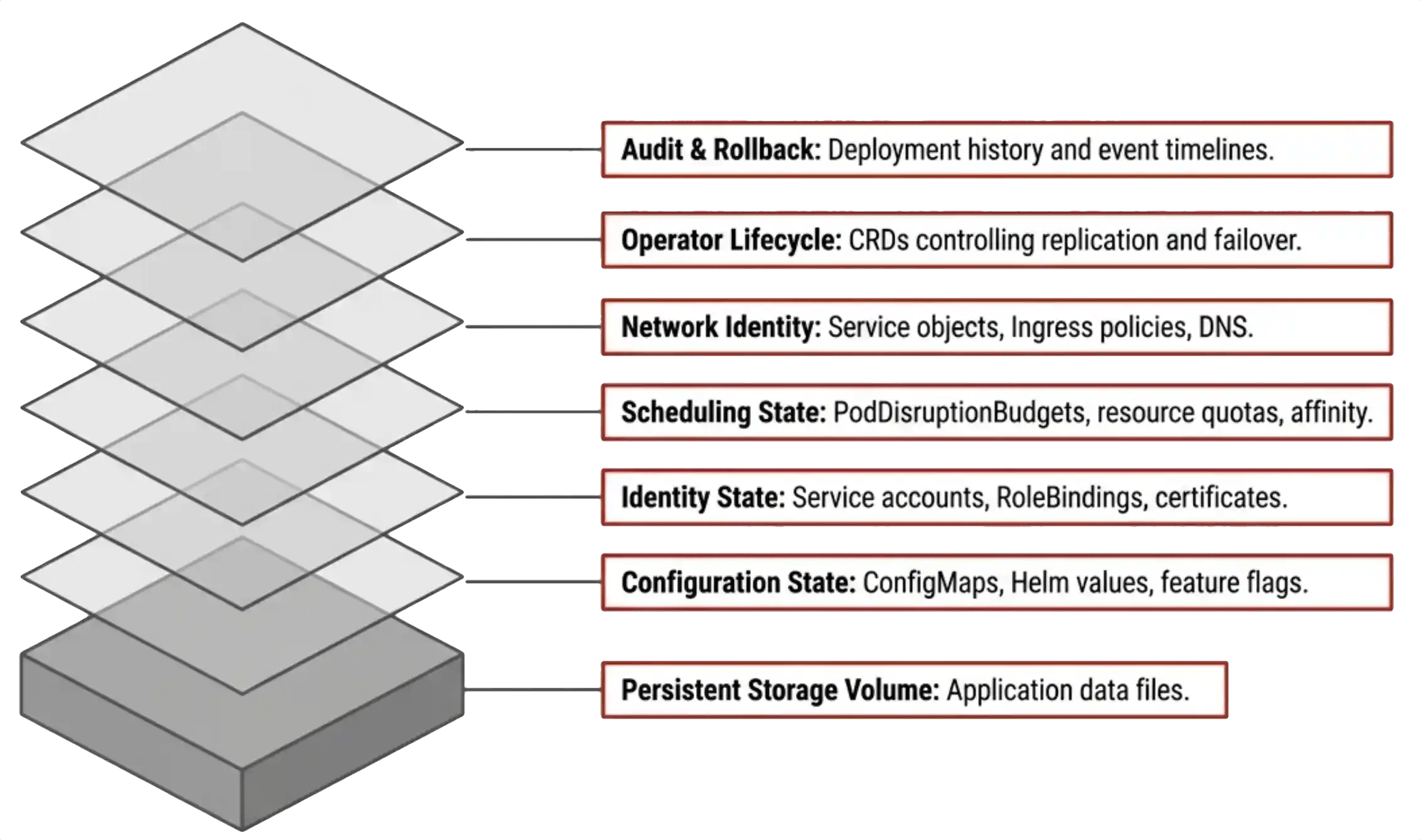
Kubernetes spreads workload state across the control plane intentionally. The design increases flexibility and orchestration capability. It also increases recovery complexity. Infrastructure teams focusing only on persistent volumes ignore most of the application definition.
Configuration state drives application behavior. ConfigMaps, Helm values, environment variables, and feature flags determine how the application runs. Restoring storage without restoring configuration produces application failures that resemble software corruption even though the data recovered correctly.
Identity state controls authentication and authorization. Service accounts, RoleBindings, image pull credentials, certificates, and token relationships define what the workload can access. Identity failures routinely surface during recovery after the storage layer comes back cleanly.
Scheduling state controls workload placement. PodDisruptionBudgets, affinity policies, autoscaling definitions, and resource quotas determine how the application behaves under load and during maintenance windows.
Network identity defines reachability. Service objects, ingress policies, DNS relationships, and NetworkPolicies determine how traffic reaches the workload. A healthy pod without a Service definition remains unavailable.
Operator lifecycle state introduces another layer of dependency. Stateful Kubernetes applications increasingly rely on operators controlling replication, scaling, failover, and lifecycle orchestration through Custom Resource Definitions. The operator’s intent lives inside the Kubernetes API. Losing that metadata leaves the storage intact and the application unrecoverable.
Audit history and rollback metadata complete the picture. Infrastructure teams need deployment history, rollback references, and event timelines that explain what the environment looked like before failure occurred.
Etcd Is the Operational Database
Most Kubernetes recovery discussions underestimate the role of etcd. The platform treats etcd as infrastructure plumbing, though operationally it behaves like the cluster’s control plane database. Kubernetes stores Secrets, ConfigMaps, Services, CRDs, RBAC relationships, namespace state, and deployment metadata inside etcd.
The cluster loses operational identity when etcd disappears.
This reality explains why CSI snapshots alone fail as a recovery architecture. Storage platforms protect persistent volume data. They do not preserve the relationships between workloads, policies, identities, and orchestration metadata stored inside the Kubernetes API. Protecting Kubernetes infrastructure means protecting both halves.
Why Fragmented Protection Fails
Traditional backup architectures evolved around stable infrastructure boundaries. Virtual machines packaged operating system, application, configuration, and runtime state into a single object. Snapshotting the VM captured nearly everything required for recovery. Kubernetes broke that model apart and distributed workload state across storage systems, control plane objects, operators, and external identity services.
Many organizations responded by layering independent protection products on top of each infrastructure component. CSI snapshots protect volume data. Kubernetes backup products capture metadata. Security tools preserve certificates. Git repositories preserve deployment manifests. VM backup products continue protecting traditional infrastructure separately.
Every protection boundary introduces a consistency boundary. The volume snapshot and the metadata export often occur at different times. The database transaction log reflects one recovery point while the operator definition reflects another. The application configuration references Secrets generated after the storage snapshot occurred. During recovery, infrastructure teams rebuild the workload manually by stitching together components captured from different moments in time.
This fragmentation creates the operational gap between backup ownership and recovery capability.
Application Consistency Still Matters
Snapshotting storage does not automatically create application consistency. A crash-consistent snapshot captures whatever existed on disk at the moment the snapshot occurred. Some workloads tolerate that model cleanly. Distributed databases and transactional systems often do not.
PostgreSQL, MongoDB, Cassandra, Kafka, and AI inference pipelines maintain transaction journals, replication queues, and in-memory state transitions that require coordinated protection behavior. The infrastructure needs application-aware orchestration capable of quiescing workloads or coordinating checkpoint operations before the snapshot occurs.
Velero, Kasten K10, Trilio, and Veeam Kasten remain important here. They capture Kubernetes metadata and coordinate API state restoration above the storage layer. The storage platform and the orchestration layer solve different parts of the recovery problem, and both have to participate for the result to function.
GitOps Does Not Replace Backup
GitOps platforms improve reproducibility and operational discipline. They do not replace infrastructure protection. Git repositories preserve desired state definitions. They rarely preserve operational state.
Production clusters contain runtime secrets, generated certificates, deployment history, persistent volume relationships, and operator state that never enters source control. Rebuilding a workload from Git reconstructs the deployment definition. It does not reconstruct the running application state at the moment failure occurred.
The direction of Kubernetes platform engineering pushes toward externalized control and reproducible infrastructure. That shift does not eliminate the recovery problem. It changes the boundaries of what requires coordinated protection.
The Maturity Curve
Most Kubernetes teams move through the same operational progression.
Stage 1 — Disposable infrastructure. Teams rely on redeployment from source control and assume Kubernetes orchestration replaces traditional recovery practices. This stage usually ends after the first serious outage.
Stage 2 — Storage-centric protection. Snapshot policies run through CSI or storage array tooling. Survivability improves, though the recovery architecture remains storage-centric instead of workload-centric.
Stage 3 — The workload is the protection boundary. Infrastructure teams recognize that applications span storage, Kubernetes metadata, network identity, authentication policy, operator lifecycle state, and traditional infrastructure dependencies. Recovery planning shifts from protecting disks to protecting operational systems.
Most enterprise Kubernetes environments operate somewhere between Stage 1.5 and Stage 2. Storage recovery works. Application recovery remains inconsistent. The second major outage usually completes the transition into platform-aware protection planning.
The Recovery Drill Exposes the Truth
The most important question in Kubernetes protection has nothing to do with backup ownership. The important question asks whether the organization has restored a complete production workload onto a clean cluster successfully.
Not just the volume. Not just the namespace. The entire application stack — Kubernetes metadata, Secrets and certificates, Services and ingress definitions, operator state, VM dependencies, authentication relationships, application configuration — restored from a coordinated recovery point. Most organizations discover their protection gaps during this exercise rather than during the original outage.
The gap closes faster when storage, snapshots, and metadata operate against a coordinated infrastructure foundation rather than across disconnected systems. Platforms that unify storage for containers and virtual machines on the same distributed file system — VergeOS is one example — narrow the recovery gap by removing the alignment problem at the infrastructure layer. The orchestration above still matters. The infrastructure below matters more than most teams admit.
Containers remain ephemeral. The workload never was.
George Crump is the CMO of VergeIO and the founder of StorageSwiss.
FAQ
Why aren’t CSI snapshots enough for Kubernetes backup?
CSI snapshots capture volume data at a point in time. They do not capture the Kubernetes objects that define how the workload runs — the Deployment, the Service, the Secrets, the ConfigMaps, the operator’s custom resource. Without those objects, the snapshot is data with no application.
What do Velero, Kasten, Trilio, and the others actually capture?
They sit above CSI. They read the Kubernetes API to capture object definitions, and they coordinate with the storage layer (often via CSI snapshots) to capture data. The output is a portable unit that contains both halves of the workload.
Does GitOps eliminate the need for Kubernetes backup?
No. GitOps preserves desired state. It does not preserve runtime secrets, generated certificates, persistent volume contents, or operator state. Production recovery needs both source-controlled definitions and operational state captured from the running cluster.
Is this only a Kubernetes problem?
No. The same problem existed for VMware workloads. The vSphere backup industry solved it by capturing VM metadata alongside VMDK data. The Kubernetes ecosystem is a decade behind on this curve and catching up quickly.
What is the smallest thing my team can do this quarter?
Pick one production namespace. Export it with an open-source tool. Restore it to a non-production cluster. Time the work. Document what was missing. That exercise produces more useful information than any vendor evaluation.
George Crump is the Chief Marketing Officer at VergeIO, the leader in Ultraconverged Infrastructure. Prior to VergeIO he was Chief Product Strategist at StorONE. Before assuming roles with innovative technology vendors, George spent almost 14 years as the founder and lead analyst at Storage Switzerland. In his spare time, he continues to write blogs on Storage Switzerland to educate IT professionals on all aspects of data center storage. He is the primary contributor to Storage Switzerland and is a heavily sought-after public speaker. With over 30 years of experience designing storage solutions for data centers across the US, he has seen the birth of such technologies as RAID, NAS, SAN, Virtualization, Cloud, and Enterprise Flash. Before founding Storage Switzerland, he was CTO at one of the nation's largest storage integrators, where he was in charge of technology testing, integration, and product selection.

[…] covers both. Disaster-recovery failover treats them as one environment rather than two. The same Kubernetes backup approach that protects a containerized workload protects its VM-based dependencies in one motion. […]