Kubernetes was originally optimized for ephemeral and stateless workloads. Containers would spin up, process requests, and disappear without retaining state between invocations. Enterprise adoption changed that model. Databases, analytics platforms, message queues, AI pipelines, and stateful application services moved into Kubernetes clusters, and persistent storage became a core infrastructure requirement rather than an edge case.
Kubernetes adapted successfully to that shift. Persistent volumes, StorageClasses, CSI drivers, VolumeSnapshots, and StatefulSets created a standardized framework for stateful workloads. The operational problem is that most environments implement those services through an assembled stack of independent products that coordinate through APIs rather than operate as a single system.
The result is a storage architecture that works, but often carries more operational coordination overhead than storage architects expect.
Key Takeaways
- Kubernetes persistent storage complexity is primarily an architectural coordination problem, not a provisioning problem.
- A typical enterprise Kubernetes storage deployment involves multiple operational layers including the storage system, CSI integration, snapshot tooling, backup software, and disaster recovery tooling.
- CSI standardized interoperability between Kubernetes and storage platforms, but it did not eliminate operational fragmentation between infrastructure layers.
- Platforms that unify storage, virtualization, snapshots, replication, and Kubernetes integration under a single control plane reduce operational surface area and cross-product coordination.
The problem is not Kubernetes itself. The problem is how persistence is commonly implemented around Kubernetes. The Container Storage Interface, the CSI driver model, persistent volumes, persistent volume claims, storage classes, and the surrounding ecosystem were all designed to let storage systems integrate cleanly with Kubernetes. That design succeeded at interoperability. It did not guarantee operational simplicity.
Key Terms
Persistent Volume (PV)
A piece of storage in a Kubernetes cluster provisioned independently of the pod that uses it. Designed to outlive any individual container.
Persistent Volume Claim (PVC)
A request for storage by a pod, including size and access mode. Kubernetes matches the claim against an available PV.
Container Storage Interface (CSI)
The standardized API that lets storage vendors expose storage systems to Kubernetes. CSI replaced the older in-tree storage driver model that shipped inside the Kubernetes code base.
StorageClass
A Kubernetes object that defines how persistent volumes are dynamically provisioned. A StorageClass references the underlying CSI driver and the provisioning parameters for the resulting volume.
Why Container Storage Became Operationally Complex
Storage architects walking into a Kubernetes deployment for the first time encounter a familiar pattern. An application team provisions a PersistentVolumeClaim. The StorageClass points the request at a CSI driver. The CSI driver communicates with a storage system that often operates outside the Kubernetes cluster on its own management plane with its own lifecycle and operational tooling. Kubernetes schedules the pod, mounts the volume, and the workload begins operating.
Each layer functions correctly. The complexity appears in coordination across those layers.
The architecture problem becomes most visible during failures or upgrades. A storage path becomes unavailable. The CSI driver reports a timeout. The pod restarts on another node and fails to remount because the underlying storage system has not yet released the attachment lock. The Kubernetes team investigates the scheduler. The storage team investigates the array. The CSI vendor investigates compatibility with the Kubernetes version. Each product behaves according to its own logic, but the operational responsibility spans multiple teams and multiple tools.
The Day 2 Operations Problem
Provisioning storage is only the beginning of the operational lifecycle. Snapshots, replication, backup, and disaster recovery introduce another layer of coordination.
Kubernetes now exposes APIs for storage orchestration, including the VolumeSnapshot framework. The underlying data services, however, usually depend on external storage systems and external tooling. Two different storage vendors can expose the same Kubernetes snapshot API and still produce very different operational behaviors, recovery workflows, retention semantics, and replication models.
Backup follows the same pattern. Many enterprise Kubernetes backup products coordinate application quiescing, CSI snapshots, metadata capture, and data movement into a separate repository. The resulting workflow often spans multiple products including the Kubernetes platform, the CSI integration layer, the storage platform, the backup application, and the recovery target.
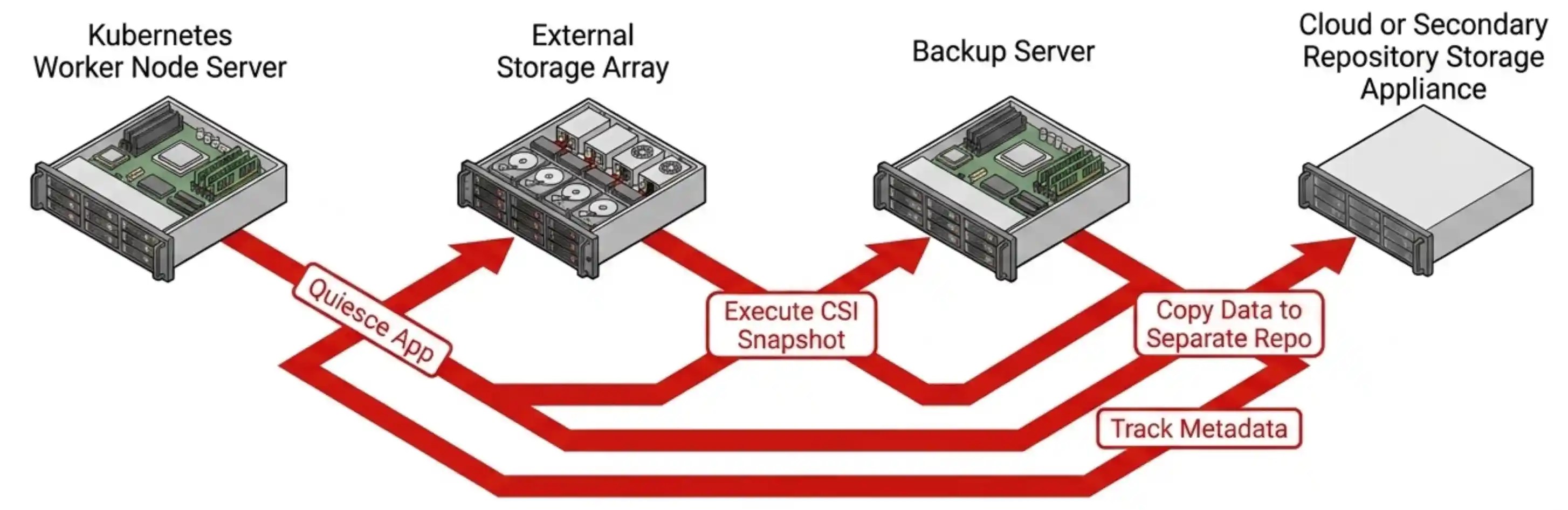
The integration works, but the operational stack becomes broader with each additional service layer.
The CSI Driver Solved Portability, Not Consolidation
CSI was a major architectural improvement for Kubernetes storage. It standardized how storage vendors integrate with Kubernetes and eliminated the older model of embedding storage drivers directly into the Kubernetes code base.
The CSI model solved portability and interoperability. It did not eliminate fragmentation between operational domains.
In traditional external-array architectures, every persistent volume request still traverses a boundary between Kubernetes and a separate storage platform with its own APIs, metadata model, snapshot engine, replication logic, monitoring tools, and upgrade lifecycle. Kubernetes coordinates storage operations through the CSI abstraction layer, but the underlying storage system still operates independently from the Kubernetes control plane.
Some Kubernetes environments reduce this separation by deploying cloud-native storage platforms such as Longhorn, Portworx, OpenEBS, or Rook/Ceph inside the cluster itself. These approaches move storage closer to Kubernetes operations, but they still introduce an additional operational layer, an additional metadata domain, and a separate storage lifecycle that platform teams must maintain.
The industry standardized integration. It did not standardize consolidation.
Kubernetes Without the VMware Tax
See one platform run virtual machines and Kubernetes side by side, with native storage, snapshots, replication, and DR. 30-minute live session and Q&A. No slideware.
A Different Architectural Model
The simplification path is structural rather than procedural. The goal is not eliminating Kubernetes abstractions. The goal is reducing the number of independent infrastructure systems participating in the storage lifecycle.
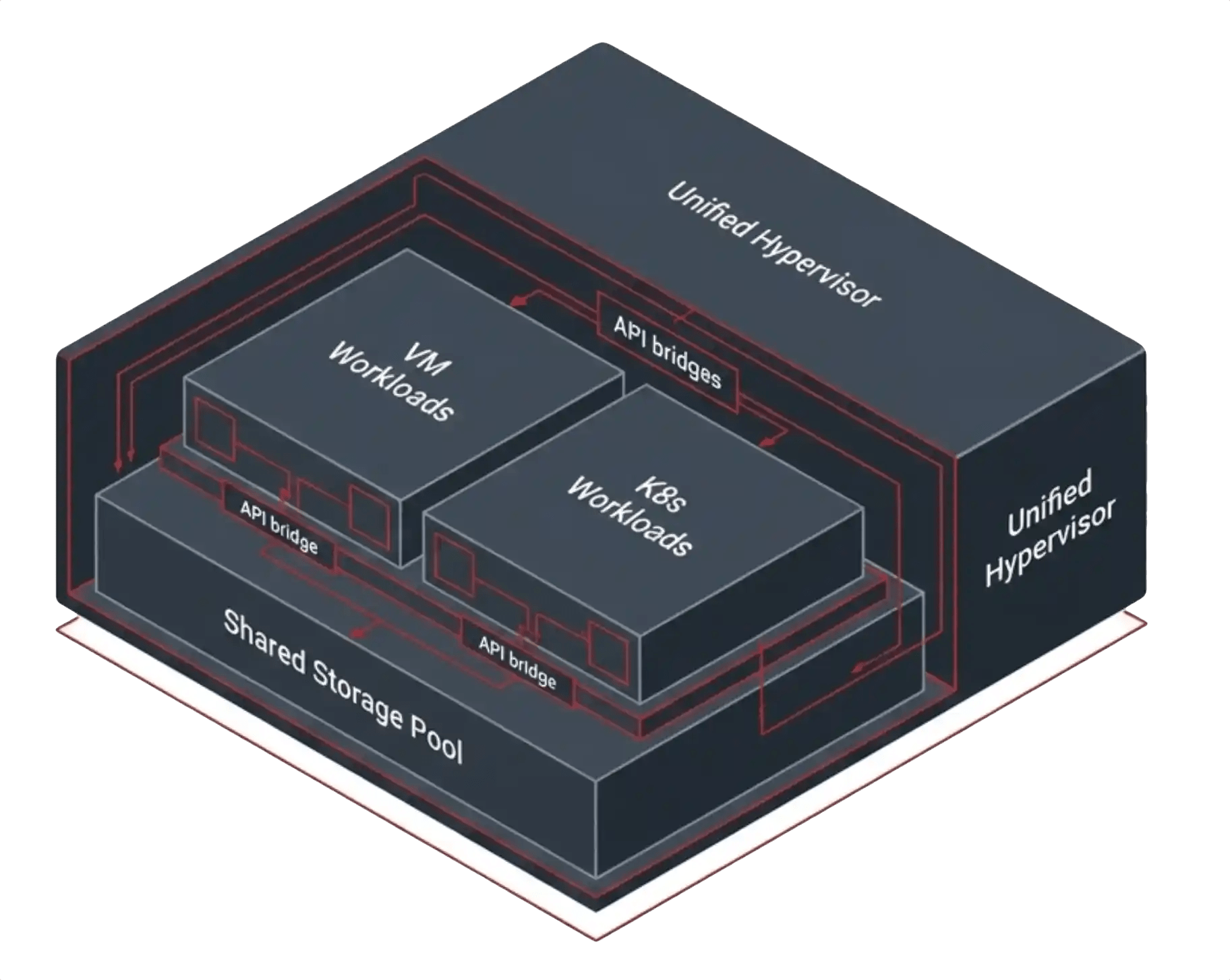 A unified infrastructure platform collapses storage, virtualization, networking, snapshots, replication, and Kubernetes integration into the same operational substrate. Kubernetes still uses CSI as its storage contract, but the CSI layer delegates directly into the same platform that owns the storage pool, replication engine, snapshot services, and recovery workflow.
A unified infrastructure platform collapses storage, virtualization, networking, snapshots, replication, and Kubernetes integration into the same operational substrate. Kubernetes still uses CSI as its storage contract, but the CSI layer delegates directly into the same platform that owns the storage pool, replication engine, snapshot services, and recovery workflow.
The integration surface shrinks dramatically because the storage system is no longer operating as a separate infrastructure product coordinated externally through APIs.
VergeOS follows this model. The platform runs virtual machines and containerized workloads on a single integrated infrastructure stack with built-in storage, snapshots, replication, and disaster recovery services. Kubernetes integration ships through native Helm charts including the CSI driver, Cloud Controller Manager, Cluster Autoscaler, and Rancher node driver.
Persistent volumes provision from the same storage pool that serves virtual machine workloads. Kubernetes still interacts through CSI semantics, but the snapshot operation resolves into a native VergeOS snapshot rather than a snapshot managed by a separate overlay storage product. Replication and disaster recovery operate through the same platform services protecting the rest of the infrastructure stack.
What Simplification Looks Like Operationally
A storage architect operating in this model provisions storage capacity once and exposes it to whichever workload class requires it. A Kubernetes StorageClass maps to the same storage pool used by virtual machine workloads. Snapshot policies operate consistently across both environments. Replication and disaster recovery use the same platform services regardless of whether the workload runs inside a VM or inside Kubernetes.
The operational result is a smaller integration surface, fewer management domains, and fewer independent infrastructure layers participating in recovery operations. The architectural result is a Kubernetes environment that behaves more like an integrated infrastructure platform than an assembled collection of storage products coordinated through APIs.
The tradeoff is reduced vendor modularity in exchange for operational consistency and consolidation. Organizations that prioritize interchangeable infrastructure components may prefer assembled architectures. Organizations focused on reducing operational coordination overhead may prefer a unified platform model.
Kubernetes persistent storage does not have to become a multi-product integration exercise. The complexity is largely a consequence of the architectural boundaries between the systems participating in the storage lifecycle. Reducing those boundaries changes the operational model.
FAQ
Does the CSI driver solve the Kubernetes storage integration problem?
CSI standardized interoperability between Kubernetes and storage platforms. It simplified portability and removed the need for vendor-specific storage code inside Kubernetes itself. The underlying storage platform, snapshot engine, replication logic, backup tooling, and disaster recovery workflows still operate across separate infrastructure domains in many environments.
Why do traditional SAN and NAS platforms create operational friction with Kubernetes?
Traditional arrays operate independently from the Kubernetes orchestration layer. Kubernetes manages persistent volumes through CSI abstractions while the storage platform maintains its own metadata, snapshots, replication policies, and lifecycle management. The coordination between those layers increases operational complexity.
What changes when storage and Kubernetes integration share the same infrastructure platform?
Kubernetes still uses standard CSI semantics, but the storage, snapshot, replication, and recovery operations resolve into the same underlying platform services. The number of independent infrastructure systems participating in the workflow decreases, which reduces operational coordination overhead.
George Crump is the Chief Marketing Officer at VergeIO, the leader in Ultraconverged Infrastructure. Prior to VergeIO he was Chief Product Strategist at StorONE. Before assuming roles with innovative technology vendors, George spent almost 14 years as the founder and lead analyst at Storage Switzerland. In his spare time, he continues to write blogs on Storage Switzerland to educate IT professionals on all aspects of data center storage. He is the primary contributor to Storage Switzerland and is a heavily sought-after public speaker. With over 30 years of experience designing storage solutions for data centers across the US, he has seen the birth of such technologies as RAID, NAS, SAN, Virtualization, Cloud, and Enterprise Flash. Before founding Storage Switzerland, he was CTO at one of the nation's largest storage integrators, where he was in charge of technology testing, integration, and product selection.

[…] https://storageswiss.com/2026/05/13/kubernetes-persistent-storage-harder-than-it-should-be/ […]