Enterprise storage discussions still spend most of their time on drive reliability. Buyers compare enterprise SSDs against consumer SSDs, new media against refurbished, endurance ratings, firmware revisions, warranty terms, and vendor qualification programs. Those conversations have merit. Drives fail, and the quality of the media matters. What has changed is the operational cost of that failure, and the storage industry has not caught up.
Key Takeaways
- Drive reliability has stopped being the deciding factor in storage architecture decisions. Recovery behavior during failure has taken its place.
- Parity-based systems force production workloads to compete with reconstruction activity for the same controller, network, and storage bandwidth.
- Replication-based architectures preserve predictable application performance during failure and simplify the write and recovery paths.
- Inline recovery capabilities such as ioGuardian close the gap when failures exceed replication tolerance.
- Refurbished enterprise SSDs become viable inside recovery-aware architectures combined with disciplined procurement.
Modern infrastructure environments run larger, denser, and longer than the architectures protecting them were designed to handle. SSD capacities keep climbing. Workloads have grown more latency-sensitive. Infrastructure teams are extending hardware life cycles under budget pressure, supply-chain instability, and AI-driven increases in flash pricing. The rapid buildout of AI factories has created a supply-and-demand imbalance across memory and NAND production, pushing enterprise SSD prices upward and stretching procurement timelines. More organizations now extend server and storage refresh cycles, evaluate mixed-generation infrastructure, and consider refurbished enterprise SSDs as a practical procurement strategy.
Key Terms
Degraded-State Operation
The period when a storage system is operating with one or more failed components and is also reconstructing data to restore its full protection level. Application performance during this state separates one storage architecture from another more than any single specification.
Parity-Based Protection
A protection scheme that distributes calculated parity information across drives and nodes to recover lost data. Capacity-efficient under normal conditions, but expensive in IO and CPU during recovery from a failed device.
Replication-Based Protection (RF2/RF3)
A protection scheme that maintains two or three full copies of each data block across nodes in the cluster. Higher raw capacity overhead than parity, but materially simpler write and recovery paths and more predictable application performance during failure.
Inline Recovery
A capability that serves missing blocks to production workloads in real time from an asynchronous recoverable copy when failures exceed the replication protection level. VergeOS implements this through ioGuardian.
Cascading Drive Failure
A failure pattern where one drive failure raises the probability of additional failures inside the same group. Drives deployed together share age, workload exposure, firmware revisions, and thermal conditions, which compresses the window between events.
The Failure Question Has Changed
The market shifts above expose an uncomfortable reality. The storage industry historically built data protection around capacity efficiency, not operational continuity during failure conditions. Most parity-based systems were designed during an era when flash economics consistently improved, refresh cycles ran shorter, and degraded-state operation was a less persistent concern.
The question infrastructure teams need to ask is not whether drives fail. All drives fail eventually. The more important question is what happens to production applications during that failure. That distinction now separates storage architectures more than the underlying media itself.
The Parity Tax During Degraded Operation
Parity-based protection gained adoption by reducing the raw capacity consumed by data protection. Parity systems distribute protection information across drives and nodes, improving usable capacity efficiency over mirrored or replicated approaches. The tradeoff is storage management overhead.
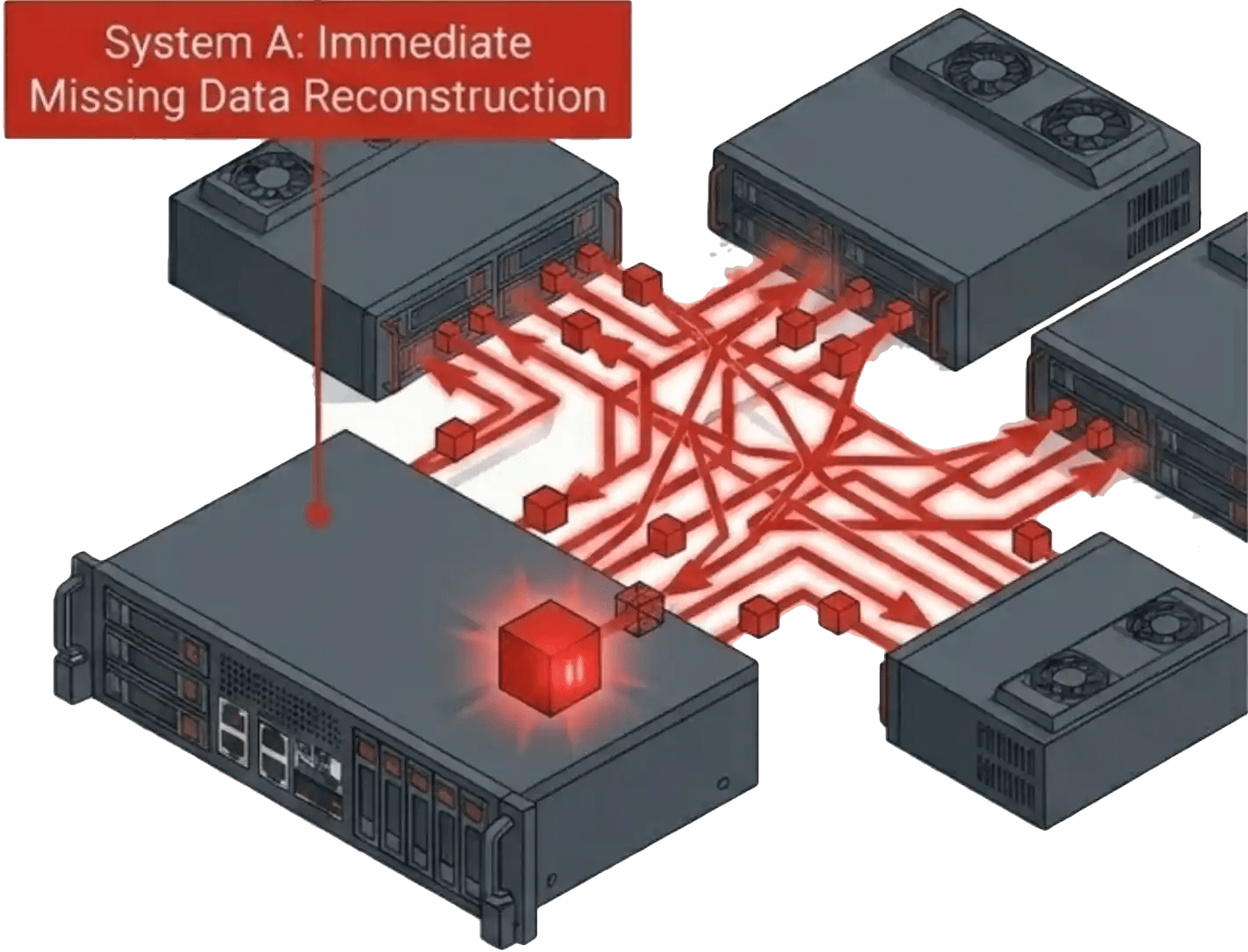
Every write requires parity calculation, stripe coordination, and distributed metadata management. Under normal conditions, modern systems handle this overhead well enough. The problem appears when the environment enters a degraded state. Once a drive fails, the storage system must reconstruct missing data and continue to service production applications at the same time. Production workloads start competing with recovery operations for the same controller, network, and storage bandwidth.
That competition shows up in application behavior. Write latency loses predictability. Database workloads see higher latency variation. Virtual desktop environments turn inconsistent during heavy login or boot activity. AI and analytics workloads see reduced throughput as the platform balances production IO against reconstruction.
The exposure grows as SSD capacities increase. Larger drives extend the time the environment operates in a degraded state. An N+1 architecture runs without its failure cushion during that window. N+2 systems still carry exposure once multiple devices fail before protection is restored.
This is not an argument that parity is unreliable. Most enterprise environments depend on it successfully. The question is whether architectures designed for capacity efficiency remain the right operational fit for environments expected to run longer, scale larger, and hold predictable performance during failure.
Replication Changes the Recovery Path
Replication-based protection handles failure differently. Instead of distributing parity, replication maintains multiple copies of data blocks across nodes in the cluster. Converged, hyperconverged, and ultraconverged architectures distribute replicated blocks across the appropriate number of nodes, keeping two or three copies of each block in the environment depending on the protection level selected.
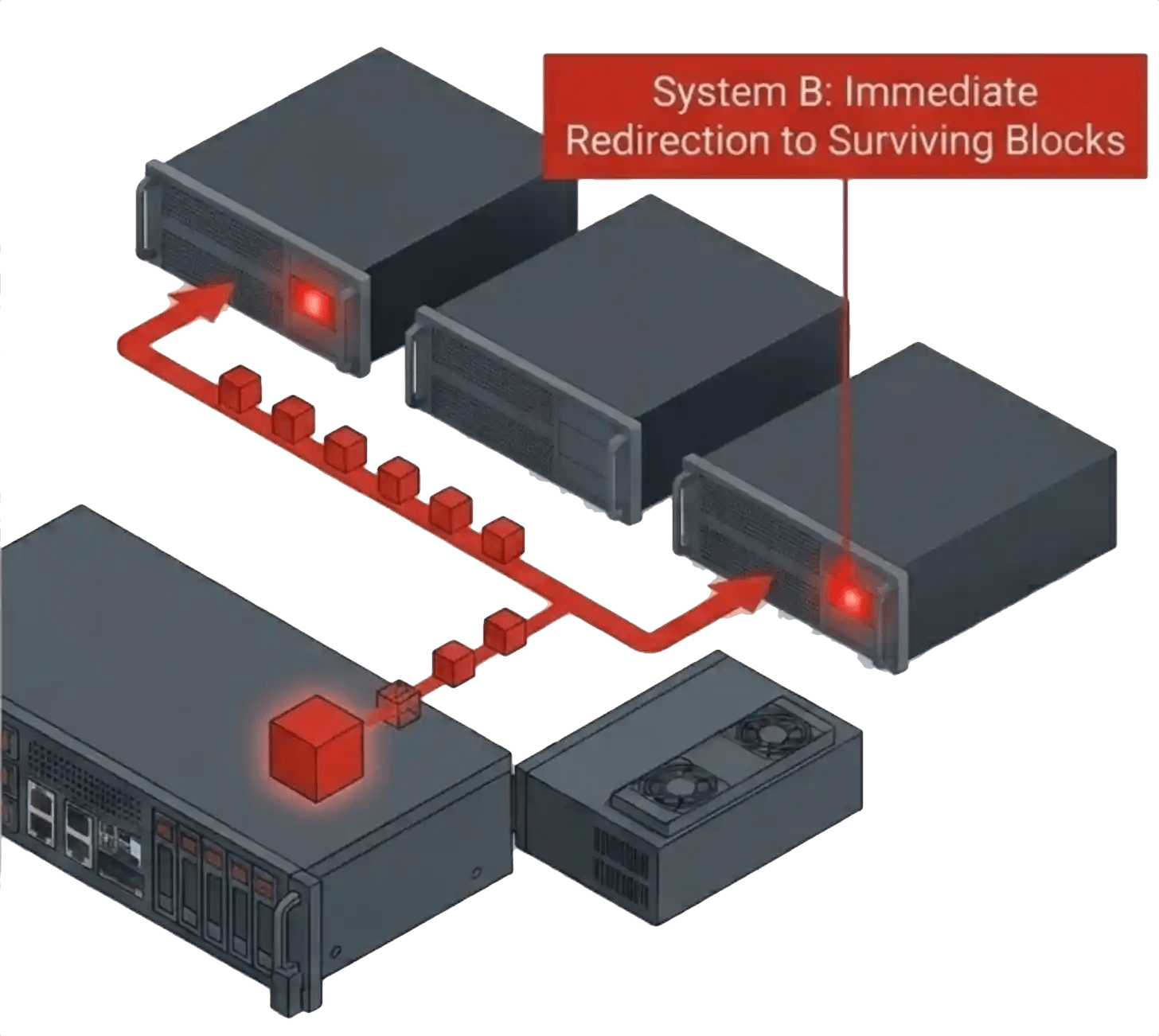
The operational advantage of replication is simplicity in the write and recovery paths. A write is acknowledged once the additional copies confirm receipt of the data. The storage system does not calculate parity, manage distributed stripe reconstruction, or rebuild missing parity blocks during degraded operation. Application performance during normal and failed-state operation stays more predictable.
Replication also changes post-failure behavior. Production applications keep reading from surviving copies without on-the-fly parity reconstruction. Recovery operations still need to occur to restore protection levels, but the immediate pressure on the environment drops. The platform focuses first on application continuity, second on rebuilding redundancy across the cluster.
The capacity argument against replication is often oversimplified. Modern parity-protected environments commonly reserve 20% to 25% of raw capacity for parity overhead, spare capacity, metadata, and operational headroom needed to hold performance and recovery behavior. The usable-capacity gap between parity and RF2 replication is smaller than the raw math suggests.
Replication-based architectures also change the lifecycle economics of the infrastructure. Predictable degraded-state performance gives organizations the confidence to extend the service life of existing hardware and SSD media. That matters in the current environment. Extending usable infrastructure life delays the need to purchase replacement flash at elevated market prices. A separate analysis lays out how the savings on a refurbished SSD-based storage refresh can fund parallel modernization decisions, including hypervisor migration.
Inline Recovery Closes the Last Gap
Several modern storage platforms now build additional recovery mechanisms on top of replication. VergeOS, for example, combines synchronous replication with a capability called ioGuardian, which maintains an asynchronous recoverable copy of the environment. When failures exceed the replication protection level, the platform keeps serving missing blocks inline to production workloads as the environment stabilizes. Other vendors implement similar concepts differently. The architectural trend is clear. Storage platforms are prioritizing application continuity during failure over storage efficiency.
Refurbished SSDs Look Different Through This Lens
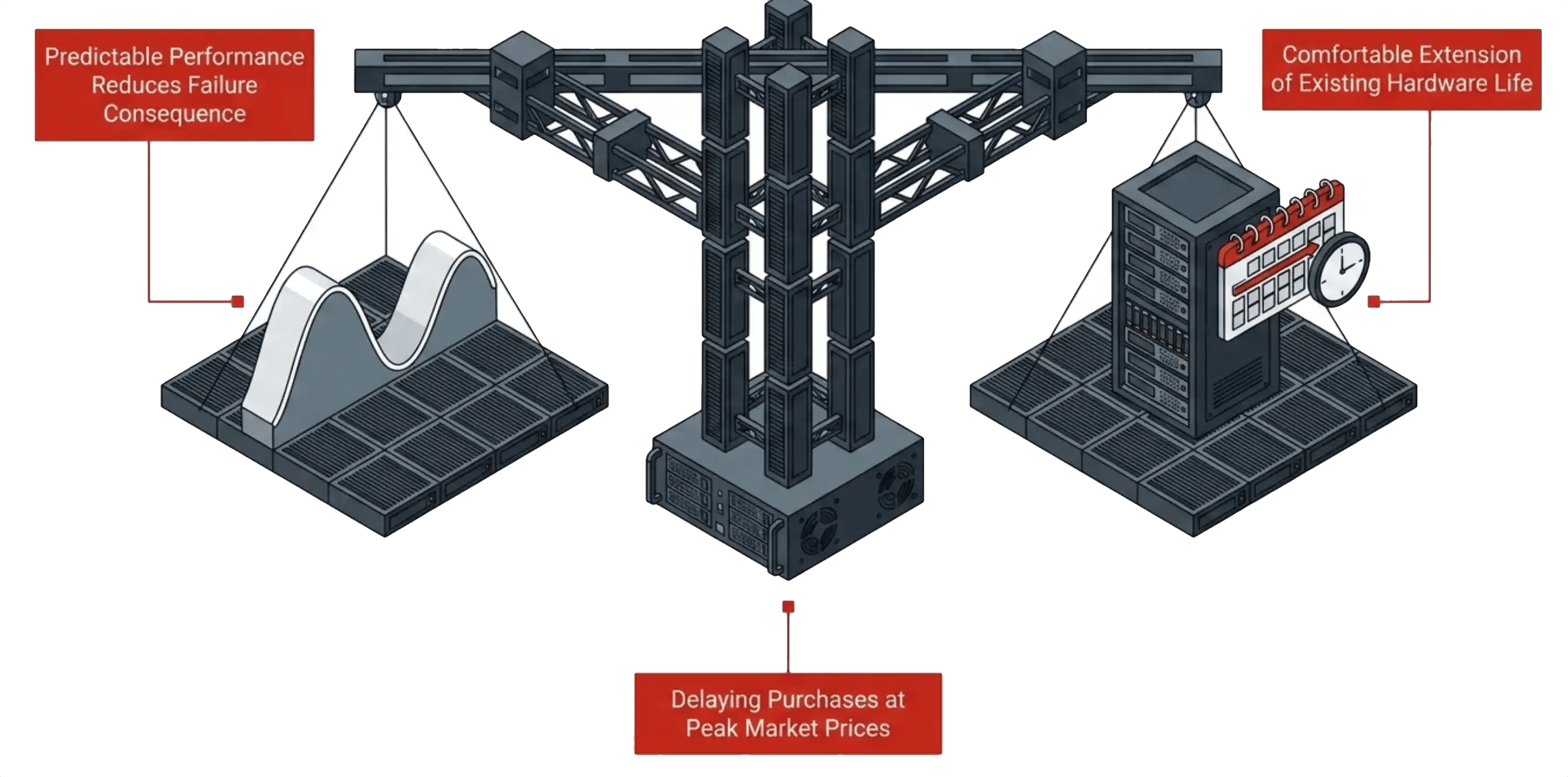
The discussion around refurbished enterprise SSDs changes inside this architectural shift. Historically, refurbished enterprise drives carried a discount against new media, but the savings rarely justified the perceived operational risk. The current flash supply crisis changed that equation. As AI infrastructure consumes more of NAND production capacity, the price gap between new and refurbished enterprise SSDs has widened, forcing organizations to revisit procurement strategies they previously dismissed.
The historical objection to refurbished media was straightforward. Older drives carried higher failure probability. In architectures where degraded-state operation creates noticeable production impact, that concern was valid. Increasing failure likelihood was hard to justify regardless of acquisition savings.
Modern storage architectures change that calculation. A platform that holds predictable application performance during degraded operation drops the operational cost of a drive failure sharply. Infrastructure teams start evaluating media differently. The conversation moves from “will the drive fail” to “how disruptive is the failure when it happens.” A companion analysis covers how platform architecture neutralizes the four supplier-side risks of refurbished enterprise SSDs, including tampered SMART data, OEM firmware lock, residual data, and batch-failure correlation.
The Cascading Failure Scenario
The recovery architecture matters most under cascading failure. Enterprise SSD failures do not always occur in isolation. Drives deployed together share age, workload exposure, firmware revisions, and thermal conditions. One failure raises the probability of additional failures inside the same group. This risk exists with both new and refurbished media. Older drives carry a higher probability of entering those failure windows sooner.
An N+1 or even N+2 protection scheme stays exposed when multiple drives fail before the environment fully restores protection. Architectures that maintain additional replication tolerance, hold predictable degraded-state performance, or layer inline recovery on top are built to absorb those scenarios.
Where the Discussion Goes From Here
Many refurbished enterprise drives still hold most of their rated endurance. They were pulled during scheduled refresh cycles, not wear exhaustion. Combined with modern SMART telemetry, wear-level monitoring, and validation testing, organizations now have far greater visibility into SSD health than they had during earlier generations of flash adoption.
Organizations adopting refurbished enterprise SSDs safely combine disciplined procurement with recovery-aware architecture. That starts with reputable suppliers, documented chain of custody, verified sanitization, and operational validation. Stated wear levels alone are not enough.
The larger point is that refurbished enterprise SSDs are no longer just a procurement discussion. Their viability now depends on the surrounding storage architecture and the platform’s ability to hold predictable application behavior during failure.
Solve the Storage Crisis With Refurbished Drives
A working session on how recovery-aware architecture changes the math on refurbished enterprise SSDs, supplier risk, and degraded-state performance.
The full set of supporting analysis on this topic, including the webinar walkthrough and the extended architectural briefing, lives on the VergeIO reference center for solving the storage crisis with refurbished drives.
Frequently Asked Questions
Is parity-based protection still safe for enterprise environments?
Most enterprise environments running parity-based protection today operate under it successfully. The question is no longer whether parity is reliable, but whether architectures built around capacity efficiency remain the right fit for environments expected to run longer, scale larger, and hold predictable performance during failure.
How does replication’s capacity overhead compare to parity in practice?
Modern parity-protected environments commonly reserve 20% to 25% of raw capacity for parity overhead, spare capacity, metadata, and operational headroom. The usable-capacity gap between parity and RF2 replication is smaller than the raw math suggests once those overheads are factored in.
What changed about refurbished enterprise SSDs in 2026?
The AI buildout has pushed NAND prices upward and stretched procurement timelines. The price gap between new and refurbished enterprise SSDs has widened to the point that organizations now treat refurbished media as a practical procurement option, especially inside architectures that hold predictable performance during failure.
What is ioGuardian and how does it differ from replication?
ioGuardian is a VergeOS capability that maintains an asynchronous recoverable copy of the environment on top of synchronous replication. When a failure scenario exceeds the replication protection level, ioGuardian continues serving missing blocks inline to production workloads as the environment stabilizes. Replication handles the first layer of failure. ioGuardian extends coverage beyond that.
How do I evaluate a refurbished SSD supplier?
Start with reputable suppliers, documented chain of custody, verified sanitization, and operational validation. SMART telemetry, wear-level monitoring, firmware validation, and rate-of-change alerting let infrastructure teams identify abnormal aging behavior early. Many organizations also perform intake stress testing on refurbished media before placing it in production.
George Crump is the Chief Marketing Officer at VergeIO, the leader in Ultraconverged Infrastructure. Prior to VergeIO he was Chief Product Strategist at StorONE. Before assuming roles with innovative technology vendors, George spent almost 14 years as the founder and lead analyst at Storage Switzerland. In his spare time, he continues to write blogs on Storage Switzerland to educate IT professionals on all aspects of data center storage. He is the primary contributor to Storage Switzerland and is a heavily sought-after public speaker. With over 30 years of experience designing storage solutions for data centers across the US, he has seen the birth of such technologies as RAID, NAS, SAN, Virtualization, Cloud, and Enterprise Flash. Before founding Storage Switzerland, he was CTO at one of the nation's largest storage integrators, where he was in charge of technology testing, integration, and product selection.
